Comparison between Apache Flink and Apache Spark
Apache Flink and Apache Spark are both distributed data processing frameworks, but they have distinct characteristics, use cases, and approaches to stream and batch processing.

1. Core Focus
Apache Flink:
Stream-first: Flink is built primarily for streaming data processing, where every piece of data is processed as a stream, even when doing batch-like operations.
Designed to provide low-latency, high-throughput, and fault-tolerant stream processing.
Apache Spark:
Batch-first, with Streaming support: Spark initially focused on batch processing and later added streaming through Spark Streaming.
Spark's Structured Streaming is designed for processing real-time data, but it was built on top of its batch processing model (micro-batch processing).
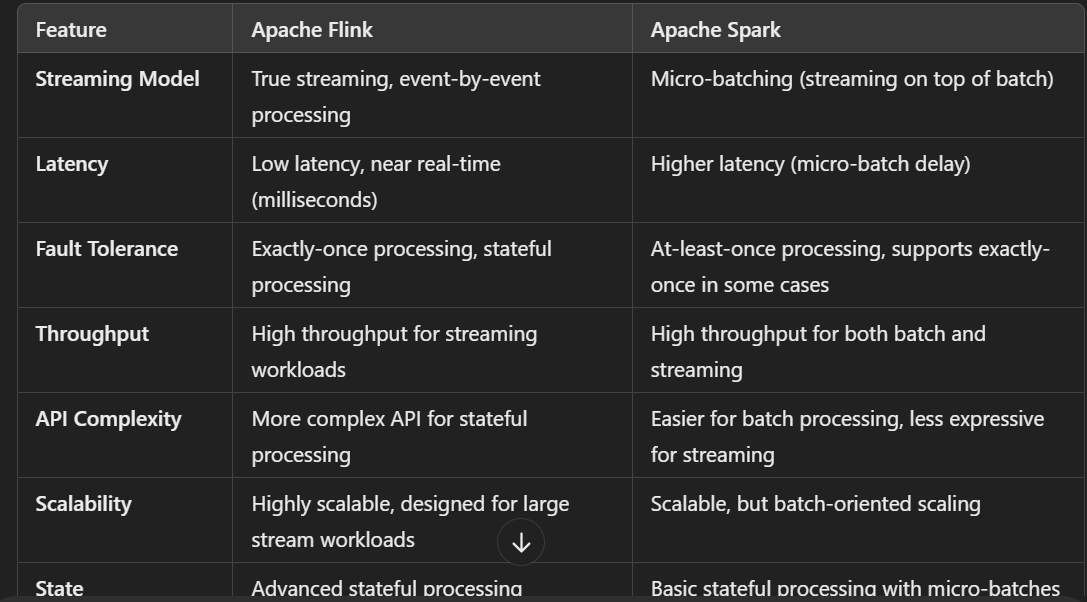
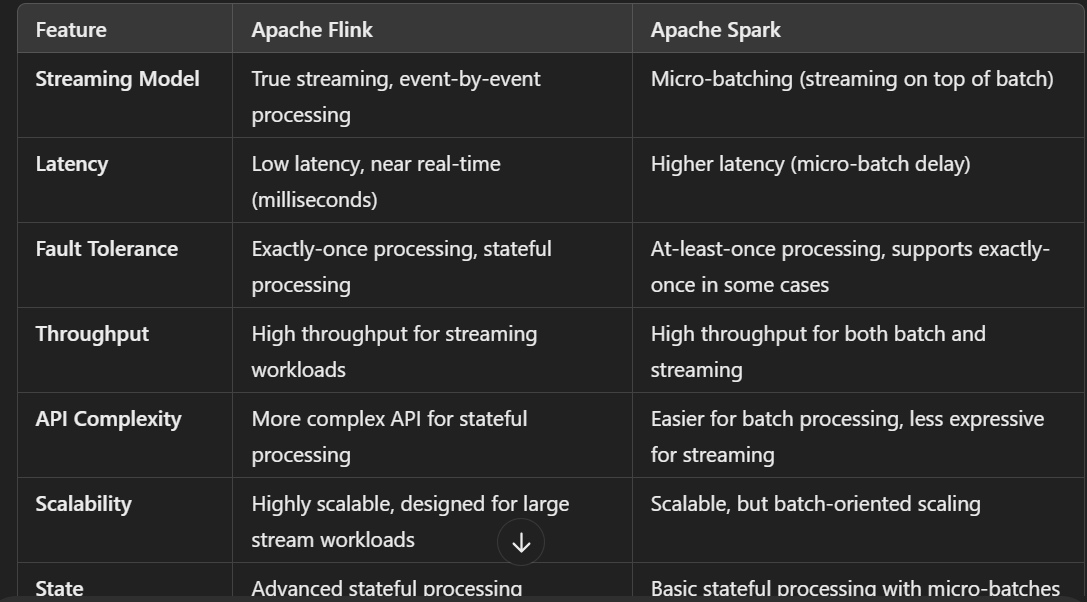
2. Streaming vs. Batch Processing
Apache Flink:
True Streaming: Flink processes data in real-time (true streaming). It processes each event as it arrives, providing low-latency processing.
Event Time Handling: Flink has strong support for event time semantics, allowing it to handle late-arriving data more effectively.
Stateful Stream Processing: Flink can maintain state across events and windows, enabling complex, long-running queries like aggregations over time.
Apache Spark:
Micro-Batching: Spark Streaming (and Structured Streaming) uses micro-batching, where incoming data is processed in small, fixed-size batches.
Not True Streaming: Because of micro-batching, it has a higher inherent latency compared to true stream processing systems like Flink.
Event Time Handling: Structured Streaming provides event-time support, but it can be more complex to work with compared to Flink.
3. Latency
Apache Flink:
Low Latency: Due to its true streaming nature, Flink has low-latency processing (typically in milliseconds).
It is often preferred when real-time or near real-time processing is crucial (e.g., for use cases like ad-click analysis, real-time fraud detection, etc.).
Apache Spark:
Higher Latency: Because Spark processes data in micro-batches, it typically has higher latency (depending on batch size, can range from a few seconds to minutes).
This makes Spark more suitable for use cases where low-latency is not critical, but batch processing is still needed.
4. Fault Tolerance and Recovery
Apache Flink:
Exactly-Once Processing: Flink supports exactly-once semantics for stream processing, ensuring that events are processed without duplication.
Flink's checkpointing and state snapshots ensure that the system can recover from failures without data loss.
Apache Spark:
At-Least-Once Processing: Spark guarantees at-least-once delivery, meaning there is a possibility of processing the same event more than once if there’s a failure.
Spark can also offer exactly-once semantics in certain use cases but requires more configuration and is typically used with Kafka or other external sinks.
5. Scalability
Apache Flink:
Flink is highly scalable, capable of handling high-throughput data streams.
It can scale both in terms of horizontal scaling and stateful operations, making it suitable for complex streaming applications.
Apache Spark:
Spark also offers good scalability, but the scalability of Structured Streaming and its batch operations can be more constrained compared to Flink, especially when handling large stateful operations.
6. APIs and Libraries
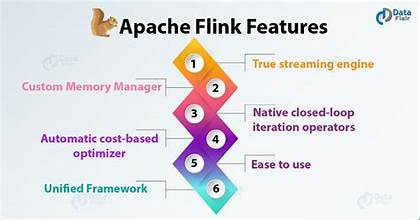
Apache Flink:
Flink has a rich set of APIs for both streaming and batch processing. It includes libraries for:
FlinkCEP: Complex event processing.
FlinkML: Machine learning (still under development).
Flink Gelly: Graph processing.
Flink’s APIs are quite expressive and support complex transformations on streaming data.
Apache Spark:
Spark provides APIs for streaming and batch data, with integration for:
MLlib: Machine learning library.
GraphX: Graph processing.
Spark SQL: SQL querying.
Structured Streaming in Spark provides an abstraction for real-time processing on top of Spark SQL, but it is still less efficient for true stream processing compared to Flink.
7. Deployment and Ecosystem
Apache Flink:
Flink is highly integrated with streaming frameworks like Kafka and supports deployment on various platforms such as Kubernetes, YARN, and Mesos.
It is designed to be lightweight and flexible, making it ideal for environments focused on real-time stream processing.
Apache Spark:
Spark is more integrated with batch processing systems, though it has improved its streaming capabilities with Structured Streaming.
It can also be deployed on Kubernetes, YARN, Mesos, and cloud platforms like Amazon EMR.
8. Community and Ecosystem
Apache Flink:
Flink is known for its real-time streaming community, with strong support for data-intensive applications and event-driven architectures.
Its ecosystem is rapidly growing, particularly for stream processing use cases.
Apache Spark:
Spark has a larger, more mature ecosystem, with widespread use in batch processing, machine learning, and data analytics.
Its community is vast, and it has a proven track record in many data engineering pipelines.
9. Use Cases
Apache Flink:
Ideal for real-time stream processing (e.g., real-time analytics, fraud detection, monitoring systems).
Complex event processing (CEP), low-latency tasks, stateful stream processing, and continuous analytics.
Apache Spark:
Best suited for batch-oriented workloads, machine learning, and large-scale data processing (e.g., ETL pipelines, batch jobs, and long-running data jobs).
While Spark Streaming can be used for real-time data, it is more suited for scenarios with micro-batch processing.
Which One to Choose?
Choose Flink if:
You need low-latency, real-time stream processing with complex event handling or stateful processing.
Your primary use case is around real-time analytics or continuous data processing.
Choose Spark if:
You need to process large batches of data with the ability to handle streaming data as an extension.
Your application involves machine learning, graph processing, or batch-oriented ETL pipelines.
Both Flink and Spark are powerful tools, but Flink is generally preferred for real-time streaming and event-driven architectures, while Spark is a great option for large-scale batch processing and analytics.