Comparison between Kafka and kinesis
Comparing Kafka and Kinesis

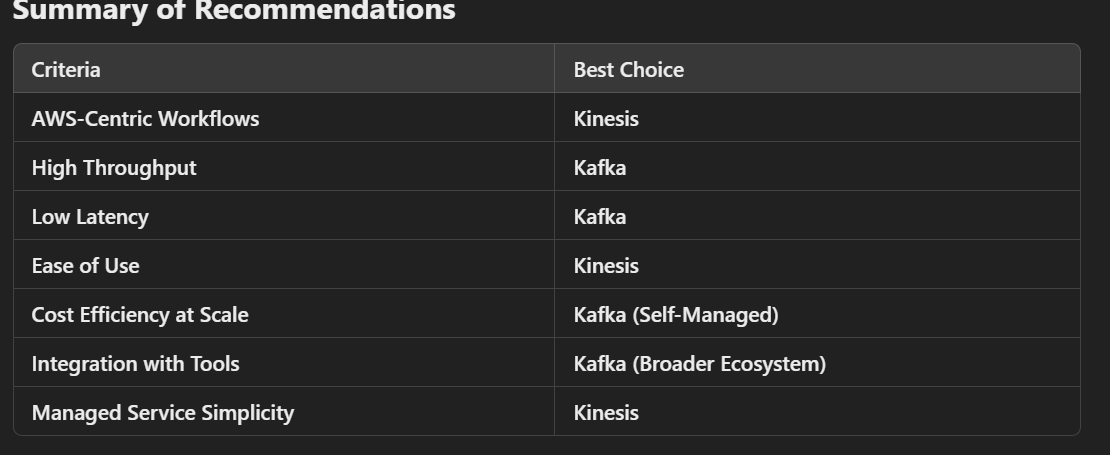
Key Factors to Consider
1. Data Volume and Throughput
Kinesis:
Throughput is tied to the number of shards. Each shard supports up to 1 MB/s write and 2 MB/s read.
Adding shards requires manual scaling or the use of Kinesis Auto Scaling.
Kafka:
Scales dynamically by adding partitions. Each partition can handle high throughput, making Kafka better suited for massive data ingestion.
Proven to handle very large-scale use cases with low latency.
Winner: Kafka for high-throughput scenarios, especially if the ad-click volume is enormous.
2. Latency
Kinesis:
Typically has slightly higher latency than Kafka.
Best suited for applications that can tolerate a few hundred milliseconds of delay.
Kafka:
Provides ultra-low latency, often in the range of a few milliseconds.
Ideal for real-time applications where low latency is critical.
Winner: Kafka for ultra-low-latency needs.
3. Integration and Ecosystem
Kinesis:
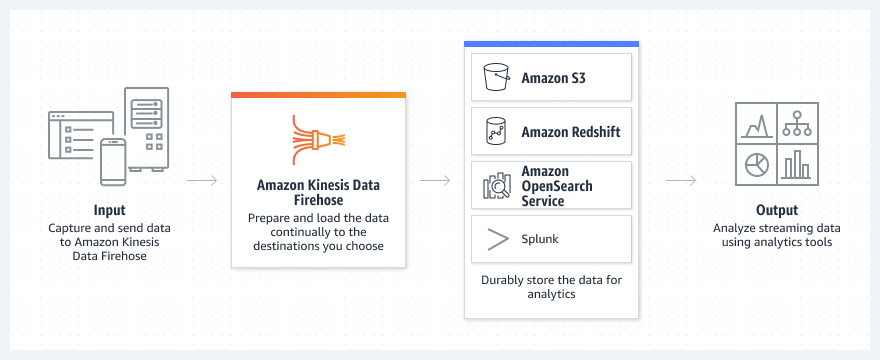
Integrates seamlessly with AWS services like Lambda, S3, Redshift, and CloudWatch.
Great for AWS-centric workloads with minimal setup.
Kafka:
Offers a broader ecosystem with connectors for various systems (via Kafka Connect).
Requires additional effort to integrate with AWS or other cloud platforms unless using a managed service like Confluent or MSK (Managed Kafka on AWS).
Winner: Kinesis for AWS-native environments; Kafka for diverse ecosystems.
4. Cost
Kinesis:
Pay-as-you-go model based on shards, data retention, and API calls.
Costs can grow rapidly with high throughput and extended retention.
Kafka:
Open-source and free to use if self-managed but involves operational overhead.
Managed services like Confluent or MSK incur additional costs but may still be more economical for high-scale use cases.
Winner: Kinesis for lower initial operational overhead; Kafka for cost-efficiency at scale (especially if self-managed).
5. Data Retention
Kinesis:
Supports retention up to 365 days, but default retention is 24 hours (can be extended).
Retention settings are limited and less flexible.
Kafka:
Retention is highly configurable, with no fixed limit.
Can store data indefinitely as long as disk space is available.
Winner: Kafka for flexible and long-term retention.
6. Ease of Use and Operational Overhead
Kinesis:
Fully managed, with no operational overhead. AWS handles scaling, maintenance, and fault tolerance.
Easy to set up and use, especially for AWS customers.
Kafka:
Requires significant expertise to manage if self-hosted (e.g., cluster setup, partitioning, replication, monitoring).
Managed Kafka services (e.g., Confluent, MSK) reduce overhead but add cost.
Winner: Kinesis for simplicity; Managed Kafka services offer a middle ground.
7. Use Case Suitability
Kinesis:
Best for simpler use cases where integration with AWS services is critical.
Suitable for applications with moderate throughput and latency requirements.
Kafka:
Better for high-throughput, low-latency, and complex use cases.
Supports advanced features like exactly-once processing (with Kafka Streams) and broader integrations.
Winner: Kafka for advanced, high-scale, and performance-critical scenarios; Kinesis for simpler AWS-native workflows.
Recommendation for Ad Click Capture
Use Case: Real-Time Ad Click Processing
Kinesis:
Works well if you're processing ad clicks in an AWS-centric environment and leveraging AWS services like Lambda, S3, or Redshift for downstream analytics.
Example: Real-time click aggregation for dashboards using Kinesis Data Analytics.
Kafka:
Ideal if you require ultra-low latency, high throughput, and integration with non-AWS tools.
Example: Streaming millions of ad clicks per second to multiple systems (e.g., data warehouses, fraud detection pipelines).
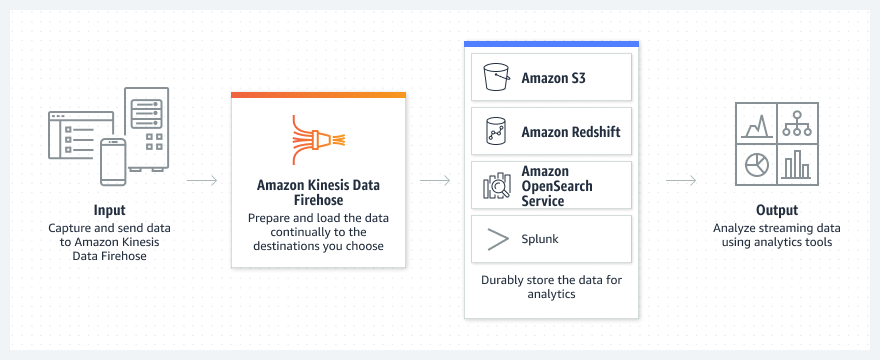
source:-wikipedia
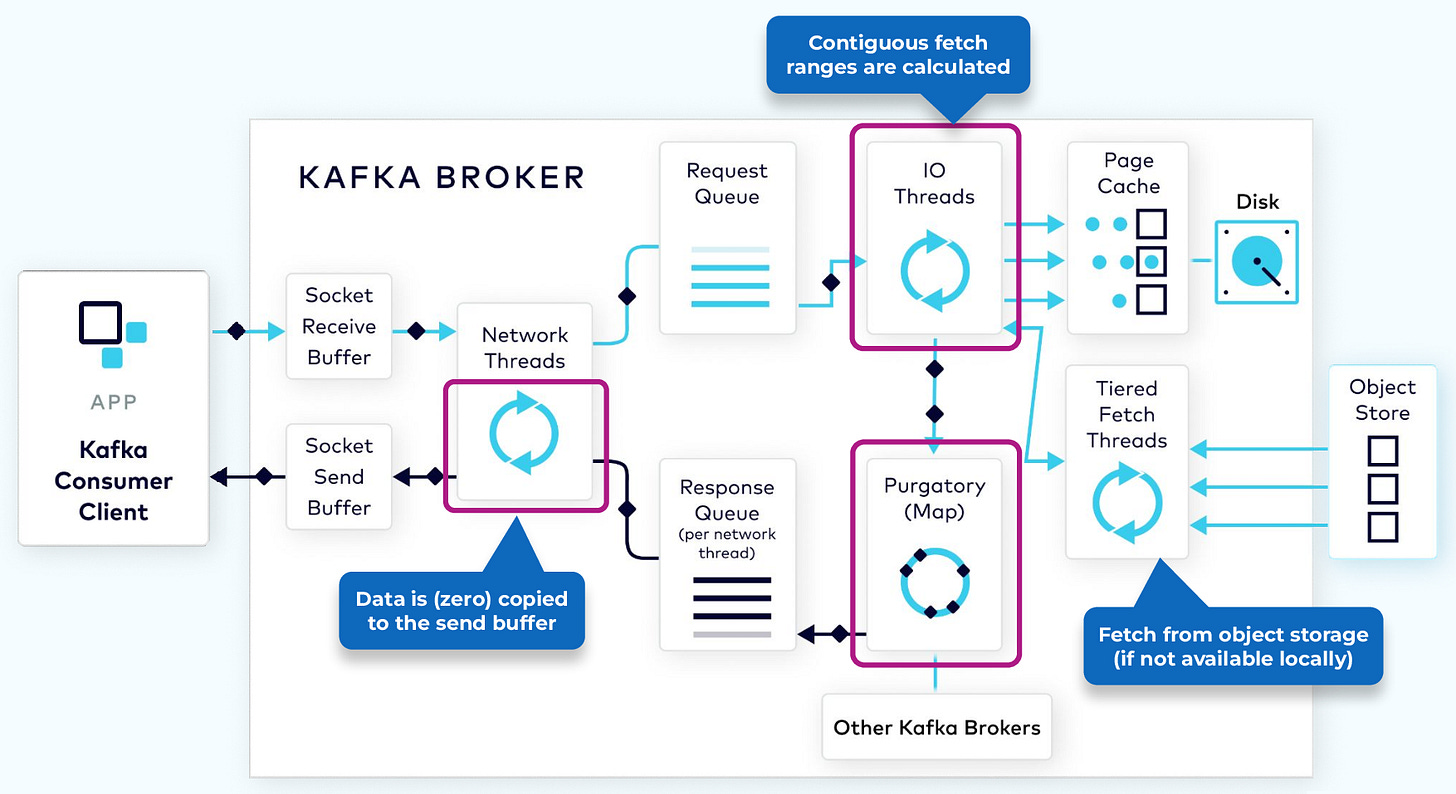
source:-wikipedia