
Connection Pooling in databases and it's advantage
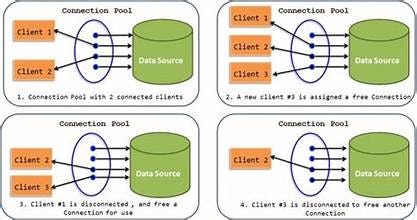
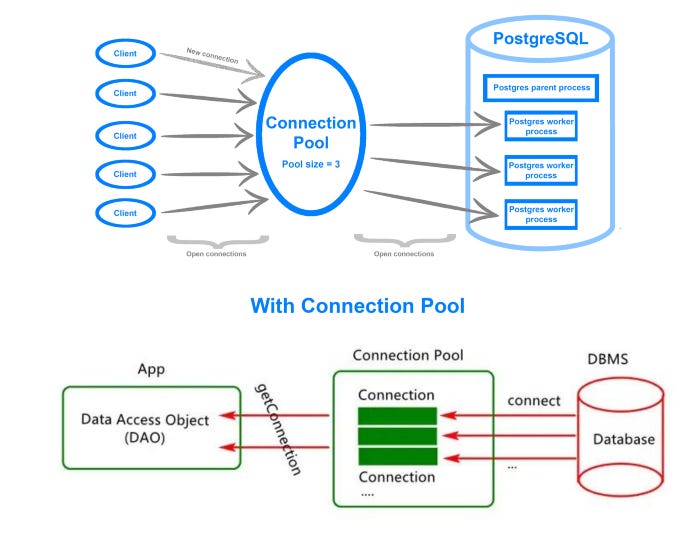
Connection Pooling is a technique used to manage database connections efficiently by reusing a pool of pre-established database connections instead of creating and closing connections for each request

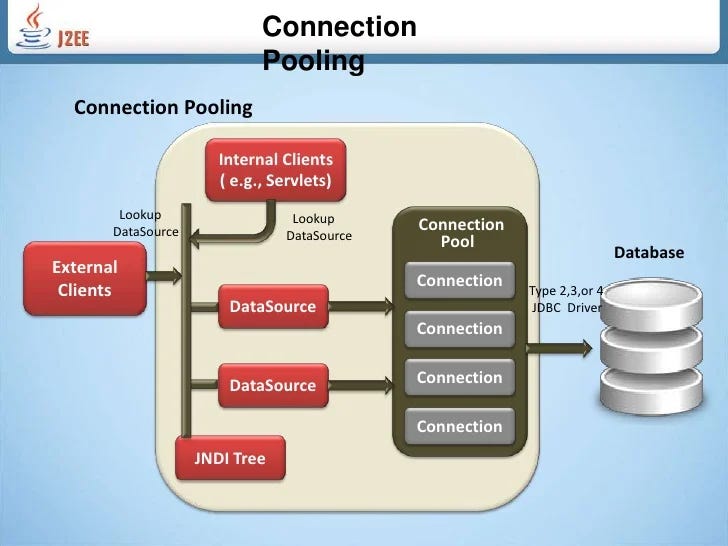
How Connection Pooling Works
Initialization: At application startup, a pool of database connections is created and maintained.
Request Handling: When a client request needs to interact with the database, it borrows a connection from the pool.
Releasing: After the database operation is completed, the connection is returned to the pool instead of being closed.
Reuse: Subsequent requests reuse these existing connections, avoiding the overhead of creating new ones.
Advantages of Connection Pooling
Performance Boost:
Establishing a database connection is a costly operation (due to authentication, network setup, etc.). Reusing connections significantly reduces the latency for database interactions.
Resource Optimization:
Limits the number of active connections to the database, preventing resource exhaustion on the database server.
Ensures efficient use of database and application server resources.
Reduced Latency:
Eliminates the overhead of repeatedly creating and tearing down connections for every database operation.
Scalability:
Enables the system to handle more database requests by efficiently managing a limited number of connections.
Particularly beneficial in high-traffic applications.
Concurrency Control:
Connection pooling enforces a cap on the maximum number of active connections to the database, helping prevent overloading.
Improved Application Reliability:
Reduces the chances of hitting connection limits by pre-allocating and managing connections systematically.
Disadvantages (Trade-offs)
Idle Connection Overhead:
Idle connections in the pool may consume resources if not managed properly.
Configuration Complexity:
Requires proper tuning of parameters like pool size, timeout, etc., to avoid resource bottlenecks or connection exhaustion.
Potential Stale Connections:
Some connections may become stale or invalid if the database restarts or experiences a network issue.
Key Configuration Parameters
When using connection pooling, you typically configure the following:
Max Connections: Maximum number of connections in the pool.
Min Connections: Minimum number of connections to maintain in the pool.
Idle Timeout: How long an idle connection remains in the pool before being closed.
Max Lifetime: Maximum time a connection can stay alive before being replaced.
Validation Query: A query to validate if a connection is alive before using it.
Example in Practice
Using HikariCP (a popular Java connection pool library):
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydb");
config.setUsername("user");
config.setPassword("password");
config.setMaximumPoolSize(10); // Max 10 connections
config.setMinimumIdle(2); // At least 2 idle connections
config.setIdleTimeout(30000); // 30 seconds idle timeout
config.setConnectionTimeout(2000); // Wait max 2 sec for a connection
HikariDataSource dataSource = new HikariDataSource(config);
Where It's Useful
Web Applications: Handling high concurrent user traffic.
Microservices: Efficiently sharing database connections in a multi-instance architecture.
Real-Time Systems: Applications requiring low-latency database queries.
Popular Connection Pooling Libraries
HikariCP (Java):
Known for its lightweight nature, high performance, and low latency.
Supports advanced features like connection validation, leak detection, and query timeout.
Apache DBCP (Database Connection Pool):
Stable and widely used.
Provides extensive documentation and supports JDBC-compliant databases.
Slightly slower than HikariCP due to additional overhead.
c3p0:
Offers built-in support for JDBC 3 and JDBC 4 specifications.
Has advanced features like connection test mechanisms and automatic recovery from database outages.
PgBouncer (PostgreSQL-specific):
Lightweight and specifically designed for PostgreSQL databases.
Works as a middleware layer between the application and database.
JDBC Connection Pool (Default in Java):
Comes bundled with Java EE (Java Enterprise Edition).
Can be used for lightweight use cases but lacks advanced features like performance tuning or monitoring.
SQLAlchemy Connection Pool (Python):
A built-in connection pooling mechanism available in SQLAlchemy ORM.
Provides configurations for pool size, timeouts, and recycling.
Key Configurations in Connection Pools
Configuring your connection pool correctly is critical for achieving optimal performance. Here's a deeper dive into important parameters:
Maximum Pool Size (
maximumPoolSize):Defines the maximum number of connections allowed in the pool.
Example: If your database can handle 100 connections, you might set the pool size to 50 to leave room for other applications.
Considerations:
Too high: May overwhelm the database.
Too low: Could lead to request queuing and increased latency.
Minimum Idle Connections (
minimumIdle):Specifies the minimum number of idle connections in the pool to handle sudden spikes in traffic.
Example:
config.setMinimumIdle(5); // Maintain at least 5 idle connections
Idle Timeout (
idleTimeout):Specifies the time (in milliseconds) a connection can remain idle before being removed from the pool.
Best Practice:
Tune this value based on your application's traffic patterns to prevent unused connections from hogging resources.
Connection Timeout (
connectionTimeout):How long the application waits for a connection to become available before throwing an exception.
Typical Value:
Between 2 to 10 seconds, depending on your application's SLA.
Max Lifetime (
maxLifetime):Defines the total lifetime of a connection before it is closed and replaced.
Helps prevent issues with stale connections (e.g., if the database kills long-lived connections).
Example:
config.setMaxLifetime(1800000); // 30 minutes
Validation Query:
A query that ensures a connection is alive before handing it over to the application.
SELECT 1Essential for detecting and discarding broken or stale connections.
Practical Considerations
When using connection pooling in your application, here are some important factors to consider:
1. Database Capacity
Know the maximum connections your database server can handle.
Example:
MySQL default: 151 connections.
PostgreSQL default: 100 connections.
Formula to Estimate Pool Size:
(CPU Cores × 2) + Effective Disk I/O ThroughputThis formula balances the CPU, I/O, and connection requirements of your application.
2. Connection Leaks
A connection leak occurs when a connection is borrowed from the pool but never returned.
Detection:
Use libraries like HikariCP that include leak detection.
Example in HikariCP
config.setLeakDetectionThreshold(2000); // Warn if connection is not returned within 2 seconds
3. Monitoring and MetricsUse tools like JMX (Java Management Extensions) or built-in monitoring in libraries (like HikariCP's metrics) to monitor:
Active connections.
Idle connections.
Wait time for connections.
Example: Export metrics to Prometheus and visualize using Grafana.
4. Connection Pool Exhaustion
If all connections in the pool are in use, new requests must wait or fail.
Mitigation:
Use queueing mechanisms or a request fallback strategy (e.g., retry logic).
5. Retries and Failures
Implement retry logic for transient failures when acquiring a connection.
Use exponential backoff to avoid overwhelming the database.
Example in a High-Load System
Imagine you're building a stock exchange system (like you're working on):
Scenario: High concurrency with thousands of orders processed every second.
Steps to Optimize:
Use a connection pool with the size configured based on the database's capacity.
Validate connections with a lightweight query (
SELECT 1).Use read replicas and route queries intelligently:
Writes: Go to the primary database.
Reads: Use a connection pool tied to replicas.
Sample Code in Python with SQLAlchemy
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker # Create a connection pool engine = create_engine( "mysql+pymysql://user:password@localhost/mydb", pool_size=10, # Max connections max_overflow=5, # Extra connections beyond pool_size pool_timeout=30, # Wait time for a connection pool_recycle=1800 # Recycle connections every 30 minutes ) # Create a session Session = sessionmaker(bind=engine) session = Session() # Use the session to query try: result = session.execute("SELECT * FROM users") for row in result: print(row) finally: session.close() # Return the connection to the pool
Let's explore read/write splitting, database failover handling, and specific pool configurations for high-demand systems like your UPI Payment App or stock exchange project.
1. Read/Write Splitting
Read/write splitting is a technique used to improve database performance and scalability by distributing read and write operations across different database replicas.
How It Works
Primary (Master): Handles all write operations and is the source of truth.
Read Replicas (Slaves): Handle read operations to offload the load from the primary.
Updates from the primary are asynchronously replicated to the replicas.
Benefits
Scalability: Offloads read-heavy workloads from the primary database.
Reduced Latency: Queries are served from geographically closer replicas.
Fault Tolerance: If a replica fails, other replicas can take over read requests.
Challenges
Replication Lag:
There’s a delay in synchronizing updates from the primary to replicas.
Can cause stale reads if a recent write hasn’t been replicated yet.
Solution: Use techniques like read-your-writes consistency or version-based validation.
Consistency Issues:
Applications must ensure that critical reads (e.g., after a financial transaction in a UPI app) go to the primary to avoid seeing outdated data.
Routing Logic:
Requires an intelligent proxy layer or application-level logic to route queries to the appropriate database instance.
Implementation Example
For a UPI Payment App:
Write operations (e.g., transferring money) go to the primary database.
Read operations (e.g., fetching transaction history) go to read replicas.
Using Proxy Tools:
Pgpool-II or HAProxy: Middleware tools that route queries based on their type (read/write).
Amazon RDS: Provides read replicas out of the box for PostgreSQL, MySQL, etc.
Example Implementation in Code (Java - Spring Boot)
Use Read/Write Splitting with a routing datasource:
Define Primary and Replica Datasources:
@Configuration public class DataSourceConfig { @Bean @Primary public DataSource primaryDataSource() { return DataSourceBuilder.create() .url("jdbc:mysql://primary-db:3306/mydb") .username("user") .password("password") .build(); } @Bean public DataSource replicaDataSource() { return DataSourceBuilder.create() .url("jdbc:mysql://replica-db:3306/mydb") .username("user") .password("password") .build(); } }
2.Create a Routing DataSource:
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager.isCurrentTransactionReadOnly() ? "REPLICA" : "PRIMARY";
}
}
3.Configure in Application:
@Bean
public DataSource routingDataSource(DataSource primaryDataSource, DataSource replicaDataSource) {
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("PRIMARY", primaryDataSource);
dataSourceMap.put("REPLICA", replicaDataSource);
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(primaryDataSource);
return routingDataSource;
}
2. Database Failover Handling
Database failover is a mechanism to switch to a backup database when the primary one fails. This ensures high availability and minimal downtime.
Strategies
Active-Passive Failover:
One primary database and a secondary standby database.
The standby takes over if the primary fails.
Active-Active Failover:
Both databases are active and can process requests.
Complex to implement but provides better performance and reliability.
Database Clusters:
Use clustered databases like PostgreSQL with Patroni, MySQL Group Replication, or Amazon Aurora.
Failover Detection
Health Checks:
Periodically check the availability of the database using a monitoring tool (e.g., Nagios, Prometheus).
Heartbeat Mechanism:
The primary database sends a "heartbeat" signal to confirm it is alive. If the signal is missed, failover is triggered.
Implementation with Middleware
Use HAProxy or Pgpool-II to automatically redirect traffic to the standby during failover.
Example HAProxy Configuration:
frontend db_traffic
bind *:3306
mode tcp
default_backend mysql_pool
backend mysql_pool
mode tcp
balance roundrobin
server primary-db 10.0.0.1:3306 check
server standby-db 10.0.0.2:3306 check backup
3. Specific Pool Configurations
Different workloads require different configurations for the connection pool.
UPI Payment App
Traffic Pattern: Spikes during business hours (e.g., 9 AM to 6 PM).
Recommended Configuration:
Max Pool Size: 100 connections (adjust based on DB capacity).
Min Idle: 20 connections to handle sudden spikes.
Validation Query:
SELECT 1to ensure connections are healthy.Timeout: 2 seconds to fail fast in case of high load.
Read Replicas: Use replicas for fetching transaction histories to offload the primary.
Stock Exchange System
Traffic Pattern: Extremely high concurrency with constant demand.
Recommended Configuration:
Max Pool Size: 500+ connections, depending on DB and application capacity.
Min Idle: 50 connections.
Connection Timeout: 1 second to handle fast failures.
Enable connection leak detection for identifying slow queries or improperly closed connections.
Use circuit breakers (e.g., Hystrix) to prevent database overload.
Practical Monitoring
Monitor Pool Metrics:
Active Connections: Number of connections in use.
Idle Connections: Number of free connections.
Wait Time: Time spent waiting for a connection.
Tools:
HikariCP Metrics with Prometheus.
Database monitoring dashboards (e.g., AWS CloudWatch, New Relic).
Alerting:
Set up alerts for:
High connection usage (> 90% of pool size).
Slow query execution times.
Frequent pool exhaustion events.
Source:-wikipedia