
Contrast between QuadTree and GeoHash and their usecases.
Both QuadTree and GeoHash are data structures/algorithms used for spatial indexing, querying, and partitioning in two-dimensional spaces

However, they have distinct properties, implementation details, and use cases. Here’s a detailed contrast between QuadTree and GeoHash and their respective use cases:
QuadTree
What is a QuadTree?
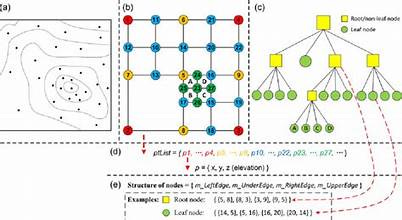
QuadTree is a tree data structure where each node represents a rectangular region of space. It recursively divides the space into four equal quadrants (hence the name "QuadTree").
Each node is either a leaf (containing spatial data points) or an internal node (divided into four child quadrants).
How it works:
The space is recursively subdivided into four quadrants (NW, NE, SW, SE) until:
A certain depth is reached, or
The number of points in a region falls below a predefined threshold.
The division enables efficient spatial querying and operations.
Key Properties:
Hierarchical Structure:
A tree-like hierarchy, with each node representing a smaller spatial region.
Dynamic Subdivision:
QuadTree can adapt dynamically to data density by dividing areas with more points into smaller quadrants.
Space-Aware:
Retains information about the exact spatial boundaries of the regions and points.
Advantages:
Efficient Spatial Queries:
Ideal for range queries (e.g., "find all points within a rectangle") because the hierarchy prunes irrelevant regions.
Handles Non-Uniform Data:
Suitable for unevenly distributed data as it only subdivides densely populated areas.
Easy Visualization:
The regions are explicit and can be easily visualized as rectangles.
Disadvantages:
Memory Usage:
The tree structure can consume significant memory, especially for highly detailed subdivisions.
Complexity:
Insertions and deletions can be more complex compared to simpler structures like GeoHash.
Use Cases:
GIS Systems:
Spatial indexing for geographic information systems to support queries like "find all cities within a bounding box."
Game Development:
Efficient collision detection or object management in a 2D game world.
Computer Graphics:
Efficient rendering of spatial data, e.g., managing terrain or image compression.
Astronomy:
Managing spatial datasets in star maps or telescopic images.
GeoHash
What is GeoHash?
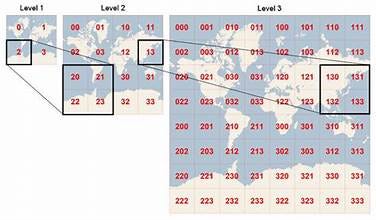
GeoHash is a spatial hashing algorithm that encodes geographic coordinates (latitude and longitude) into a single string or integer.
It represents 2D space as a linear sequence by recursively dividing it into grids.
How it works:
The space (e.g., the globe or a 2D map) is divided into a grid. Each grid cell is recursively subdivided into smaller grids.
The latitude and longitude of a point are interleaved and encoded as a binary representation, which is then converted into a Base32 string or integer.
Key Properties:
Hashing-Based:
Encodes spatial data into compact, fixed-length strings or integers.
Fixed Resolution:
The precision depends on the length of the GeoHash string (longer strings = finer resolution).
Spatial Proximity:
Neighboring regions have similar GeoHashes, making it efficient for proximity-based queries.
Advantages:
Compact Representation:
Spatial coordinates are encoded into compact strings, making it easy to store and index.
Proximity Search:
Supports proximity queries (e.g., "find locations near a given point") since nearby areas have similar GeoHash prefixes.
Efficient Indexing:
GeoHash works well with indexing systems like databases (e.g., it can be used as a key in a database).
Disadvantages:
Loss of Spatial Accuracy:
GeoHash uses a grid-based approximation, so spatial precision decreases for large regions.
Non-Uniform Data:
Handles non-uniformly distributed data poorly as it always divides space into uniform grids, even if some areas are sparse.
Neighbor Lookup Overhead:
For proximity queries, nearby GeoHashes must often be explicitly computed.
Use Cases:
Location-Based Services:
Encoding and querying location data in applications like Uber, Swiggy, or Google Maps.
Distributed Systems:
Spatial partitioning in distributed systems for storing and querying geospatial data.
Key-Value Databases:
GeoHash strings are often used as keys for geospatial indexing in NoSQL databases (e.g., DynamoDB or Cassandra).
Proximity Search:
Applications where finding "nearest neighbors" or "locations near a point" is important.


Choosing Between QuadTree and GeoHash
Use QuadTree when:
You need precise spatial boundaries for objects or regions.
Data is non-uniformly distributed, and some regions are denser than others.
You require efficient range queries (e.g., finding all points in a rectangle).
The application involves dynamic data with frequent insertions/deletions (e.g., games, GIS systems).
Use GeoHash when:
You need a compact representation of spatial data for indexing in a database.
Your application involves proximity-based searches (e.g., "find locations near me").
The spatial data is uniformly distributed, or the grid approximation is acceptable.
You're working in a distributed system where spatial keys need to be mapped across nodes.
Real-World Examples
QuadTree:
Used in geographic information systems (GIS) like ArcGIS.
In games for managing and querying objects in a 2D space (e.g., collision detection in Unity).
Astronomy for spatial indexing in large star catalogs.
GeoHash:
Used by location-based services like Uber or Google Maps for geospatial indexing and proximity search.
Spatial indexing in distributed databases (e.g., Cassandra, DynamoDB).
Applications requiring location search in fixed-sized grids (e.g., food delivery apps).
In conclusion, both QuadTree and GeoHash are powerful spatial data structures, but the choice between them depends on the specific use case requirements such as accuracy, query type, data distribution, and system architecture.