Design a Trending Topics System with focus on: count-min sketch, sliding window, ranking
Breakdown of the functional requirements for a Trending Topics System with focus on count-min sketch, sliding window, and ranking:

Let’s look into FR
1.System should ingest large-scale event streams (e.g., tweets, posts, hashtags, keywords).
2.Maintain approximate counts of occurrences of each topic using count-min sketch to reduce memory overhead.
3.Support queries like:
“How many times has topic X appeared in the last N minutes?”
“What are the top-K topics in the current window?”
4.Support time-based sliding windows (e.g., last 5 minutes, 1 hour) to determine currently trending rather than historically popular topics.
5.Rank topics based on frequency in the current sliding window.
6.Allow queries for trends at different time granularities:
e.g., top hashtags in last 10 min, 1 hour, 1 day.
NFR
1.New events should be reflected in trending results within a few seconds (sub-second ideal).
2.Handle high write throughput (millions of events per second globally).
3.Since count-min sketch is approximate, system must guarantee:
Upper bound on overestimation error (ε).
High probability of accuracy (1 − δ).
4.System should have high availability (99.9%+ SLA) even during peak traffic.
5.Eventual consistency acceptable (eventual consistency) since trending topics are approximate.
Back of envelope
Writes (Ingestion QPS)
Each incoming event = 1 write (update CMS + Top-K).
If ingestion rate = 1M events/sec, → Write QPS ≈ 1M.
Per shard (S = 10): 100k writes/sec.
Reads (Query QPS)
Typical queries:
Get top-K trending topics → reads Top-K heap (O(log K) or just cached list).
Get count of a topic → CMS lookup (O(d), ~7 reads).
Query traffic is usually much lower than ingestion (<< writes).
Assume ~10k queries/sec globally (common for API consumers, dashboards,Storage
API’s
🔹 1. Ingest Event
Purpose: Push a new event (topic/keyword/hashtag) into the system.
POST /api/v1/events
{
“topic”: “worldcup2025”,
“userId”: “u12345”,
“timestamp”: “2025-09-28T10:05:32Z”,
“metadata”: {
“lang”: “en”,
“region”: “IN”,
“source”: “twitter”
}
}
response
{
“status”: “success”,
“message”: “Event ingested”,
“topic”: “worldcup2025”
}
🔹 2. Get Count of a Topic (in window)
Purpose: Retrieve approximate frequency of a topic in a sliding window.
GET /api/v1/topics/{topic}/count?window=5m
Response
{
“topic”: “worldcup2025”,
“window”: “5m”,
“count_estimate”: 128947,
“error_bound”: “±0.1%”
}
🔹 3. Get Top-K Trending Topics
Purpose: Return top-K topics in a given time window.
GET /api/v1/trending?window=10m&top=5®ion=IN
Response
{
“window”: “10m”,
“region”: “IN”,
“top”: 5,
“topics”: [
{ “topic”: “worldcup2025”, “count_estimate”: 1823947 },
{ “topic”: “newiphone”, “count_estimate”: 1593821 },
{ “topic”: “stockmarket”, “count_estimate”: 1293847 },
{ “topic”: “bigboss”, “count_estimate”: 1002834 },
{ “topic”: “climatechange”, “count_estimate”: 934827 }
],
“error_bound”: “±0.1%”
}
🔹 4. Get Trend History
Purpose: Retrieve historical trend snapshots for a topic or for all topics.
GET /api/v1/topics/{topic}/history?window=1h&granularity=5m
Response
{
“topic”: “worldcup2025”,
“window”: “1h”,
“granularity”: “5m”,
“trend”: [
{ “timestamp”: “2025-09-28T09:00:00Z”, “count_estimate”: 18234 },
{ “timestamp”: “2025-09-28T09:05:00Z”, “count_estimate”: 20193 },
{ “timestamp”: “2025-09-28T09:10:00Z”, “count_estimate”: 21593 },
{ “timestamp”: “2025-09-28T09:15:00Z”, “count_estimate”: 22894 }
],
“error_bound”: “±0.1%”
}
🔹 5. Admin/Monitoring APIs
Health Check
GET /api/v1/health
{
“status”: “healthy”,
“uptime_sec”: 102349,
“ingestion_rate_eps”: 987654,
“query_rate_qps”: 123
}
Metrics
GET /api/v1/metrics
{
“cms_memory_mb”: 9.2,
“topk_memory_mb”: 1.6,
“window_size”: “60m”,
“active_buckets”: 60,
“error_bound”: “±0.1%”
}
Databases
🔹 Database Choices
We need to handle 3 different data types:
Fast-moving counters (CMS + Top-K)
High write QPS (millions/sec).
Memory-first data structure, backed by lightweight persistence.
DB Role: Checkpoint & recovery.
✅ Recommended:
Redis / RocksDB for CMS + Top-K state persistence.
Or Kafka log + periodic snapshots to S3 (durability).
Raw Event Stream (optional retention)
If you need to reprocess or audit raw events.
✅ Recommended:
Kafka / Pulsar for streaming ingestion.
S3 / HDFS for long-term storage.
Trend History (aggregated results)
Lower write rate (per minute/hour).
Queried frequently for dashboards & APIs.
✅ Recommended:
Time-series DB (TimescaleDB, ClickHouse, InfluxDB) → optimized for window queries.
Or Cassandra/DynamoDB for wide-column storage.
📌 SQL Schemas
1. Raw Events (optional, for audit/replay)
CREATE TABLE events (
topic_id VARCHAR(255) NOT NULL,
event_time TIMESTAMP NOT NULL,
user_id VARCHAR(255),
region VARCHAR(50),
lang VARCHAR(10),
source VARCHAR(50),
payload JSONB,
PRIMARY KEY (topic_id, event_time)
);
2. Count-Min Sketch Buckets (serialized state)
CREATE TABLE cms_buckets (
bucket_id BIGINT NOT NULL, -- epoch_minute
shard_id INT NOT NULL,
width INT NOT NULL,
depth INT NOT NULL,
counters BYTEA NOT NULL, -- serialized 2D array
updated_at TIMESTAMP NOT NULL,
PRIMARY KEY (shard_id, bucket_id)
);
3. Top-K Topics per Window
CREATE TABLE topk_topics (
window_start TIMESTAMP NOT NULL,
window_end TIMESTAMP NOT NULL,
region VARCHAR(50) NOT NULL,
rank INT NOT NULL,
topic VARCHAR(255) NOT NULL,
count_estimate BIGINT NOT NULL,
PRIMARY KEY (region, window_start, rank)
);
4. Topic Trend History (aggregated)
CREATE TABLE topic_trend_history (
topic VARCHAR(255) NOT NULL,
window_start TIMESTAMP NOT NULL,
window_end TIMESTAMP NOT NULL,
region VARCHAR(50) NOT NULL,
count_estimate BIGINT NOT NULL,
PRIMARY KEY (topic, window_start, region)
);
📌 Notes
events→ optional, only if you want replay/audit.cms_buckets→ stores sliding window CMS snapshots (for recovery & merging).topk_topics→ serves/trendingAPI.topic_trend_history→ serves/historyAPI.
📌 Cassandra CQL Schemas
1. Raw Events (optional)
CREATE TABLE events (
topic_id TEXT,
event_time TIMESTAMP,
user_id TEXT,
region TEXT,
lang TEXT,
source TEXT,
payload TEXT, -- store JSON string if needed
PRIMARY KEY ((topic_id), event_time)
) WITH CLUSTERING ORDER BY (event_time DESC);
🔹 Partitioned by topic_id → efficient per-topic queries.
🔹 Ordered by event_time → efficient time-range scans.
2. Count-Min Sketch Buckets
CREATE TABLE cms_buckets (
shard_id INT,
bucket_id BIGINT, -- epoch_minute
width INT,
depth INT,
counters BLOB, -- serialized CMS 2D array
updated_at TIMESTAMP,
PRIMARY KEY ((shard_id), bucket_id)
) WITH CLUSTERING ORDER BY (bucket_id DESC);
🔹 Partitioned by shard_id.
🔹 Buckets ordered by time for sliding window eviction.
3. Top-K Topics per Window
CREATE TABLE topk_topics (
region TEXT,
window_start TIMESTAMP,
rank INT,
topic TEXT,
count_estimate BIGINT,
PRIMARY KEY ((region, window_start), rank)
);
🔹 Partitioned by (region, window_start) → efficient query:
SELECT * FROM topk_topics WHERE region=’IN’ AND window_start=’2025-09-28T10:00:00Z’;
4. Topic Trend History (Aggregates)
CREATE TABLE topic_trend_history (
topic TEXT,
region TEXT,
window_start TIMESTAMP,
count_estimate BIGINT,
PRIMARY KEY ((topic, region), window_start)
) WITH CLUSTERING ORDER BY (window_start DESC);
🔹 Partitioned by (topic, region).
🔹 Sorted by window_start for fast history scans.
HLD
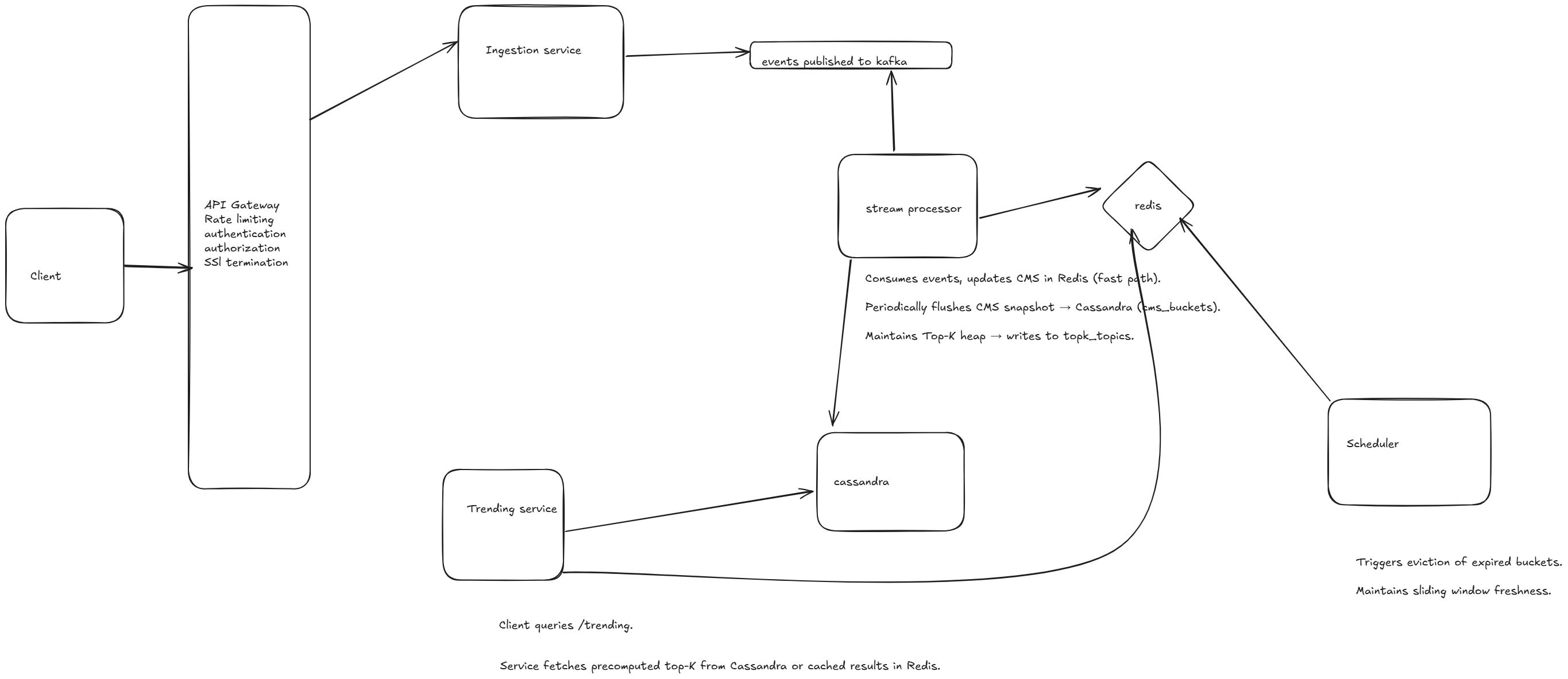
📌 Microservices Architecture
1. Ingestion Service
Role: Receives raw events (tweets, posts, searches, etc.).
Tasks:
Parse event.
Publish to Kafka (or other event bus).
Optional write to
eventstable (Cassandra) for replay/audit.
Interfaces:
POST /event→ push single/bulk events.
Scale: Horizontally scalable, stateless.
2. Stream Processor
Role: Real-time consumer of Kafka events.
Tasks:
Update Count-Min Sketch (Redis / in-memory CMS).
Maintain sliding window buckets.
Periodically compute Top-K per window.
Write results into:
cms_buckets(Cassandra) for durability.topk_topics(Cassandra) for serving queries.
Scale: Partitioned by topic_id / region to parallelize.
3. Trending Service
Role: API layer for clients (dashboards, apps).
Tasks:
Fetch Top-K trending topics from Cassandra (
topk_topics) or cache.Fetch topic history (
topic_trend_history).Query current CMS for approximate count of a topic.
Interfaces:
GET /trending?region=IN&window=1hGET /topics/{id}/history?region=IN&period=24hGET /topics/{id}/count?window=1h
4. Scheduler / Window Manager
Role: Orchestrates window sliding.
Tasks:
Every X minutes: expire old buckets, trigger top-K recomputation.
Insert new row in
topk_topics.
Interfaces: Internal (cron / job).
5. Storage Layer
Cassandra →
cms_buckets,topk_topics,topic_trend_history,events.Redis / Memcached → Hot CMS state + caching trending queries.
6. Analytics / Dashboard Service (optional)
Role: Used by ops/analysts.
Tasks:
Show trending topics globally or per region.
Provide insights (growth rate, anomalies).
Interfaces: Internal dashboards.
📌 Interaction Flow (Step-by-step)
Client → Ingestion Service
Sends new event (
topic=”Elections”, user_id=123).
Ingestion Service → Kafka
Publishes normalized event.
Stream Processor → Kafka
Consumes events, updates CMS in Redis (fast path).
Periodically flushes CMS snapshot → Cassandra (
cms_buckets).Maintains Top-K heap → writes to
topk_topics.
Trending Service → Cassandra / Redis
Client queries
/trending.Service fetches precomputed top-K from Cassandra or cached results in Redis.
Scheduler → Stream Processor + Storage
Triggers eviction of expired buckets.
Maintains sliding window freshness.
👉 Think of it like this:
Fast Path (real-time): Redis CMS + Top-K heap.
Durable Path (historical): Cassandra for queries and recovery.
HLD