
Design Ad click aggregator
An Ad Click Aggregator collects, processes, and summarizes click data for advertisements to generate insights and analytics.

FR
1.Capture ad click events in real-time or near real-time.
2.Aggregate click events by multiple dimensions (e.g., time intervals, ad ID, campaign ID, user segments, and geography).
3.Generate metrics such as total clicks, unique clicks, and click-through rates (CTR).
4.Handle duplicate or incomplete click events gracefully.
5.Generate dashboards or downloadable reports for different time frames and campaigns
6.Allow users to query click data with various filters (e.g., by ad ID, campaign, location, etc.)<100ms.
7.User should be able to place ads
8.Advertisers can query ad click metrics over time with a minimum granularity of 1 minute
NFR
1.Ensure click data is stored reliably and is recoverable in case of system failures,making system highly durable
2.Provide eventual consistency in aggregated data across distributed systems.
3.Enable low-latency querying of aggregated data for real-time analytics.
4.System should be highly scalable to handle millions of ad click events per second.
5.System should be highly available to capture ad clicks
Estimates
Traffic
Daily active users (DAU): 100 million users.
Each user clicks on ads 5 times per day.
Total daily clicks = 100M*5=500M
write QPS=500M/10^5=5k QPS
views QPS= 5k*100=500kQPS
Storage
Average event size = 500 bytes (includes metadata like user ID, ad ID, timestamp, campaign ID, location, etc.).
Total storage=500M*500bytes=250Kb* M=250GB
Retention period is 90 days=250GB*90=25TB API’s
1.POST /api/v1/clicks
Captures a single ad click event or batch of events
request {
"events": [
{
"user_id": "12345",
"ad_id": "ad_9876",
"campaign_id": "camp_456",
"timestamp": "2024-12-20T12:34:56Z",
"geo": "US",
"device": "mobile",
"referrer": "https://example.com"
}
]
}
response {
"status": "success",
"message": "Event(s) recorded successfully"
}
2.GET /api/v1/metrics/realtime
Retrieves real-time metrics for a specific ad or campaign.
Query Parameters:
ad_id(optional): Filter by ad ID.campaign_id(optional): Filter by campaign ID.time_range: e.g.,last_5_min,last_1_hour.
response {
"ad_id": "ad_9876",
"campaign_id": "camp_456",
"metrics": {
"total_clicks": 1234,
"unique_clicks": 987,
"ctr": 0.45
}
}
3.GET /api/v1/metrics/historical
Description: Fetches aggregated data for historical analysis.
Query Parameters:
ad_id(optional): Filter by ad ID.campaign_id(optional): Filter by campaign ID.start_date: Start of the time range (ISO 8601 format).end_date: End of the time range (ISO 8601 format).group_by: Dimensions to group by (e.g.,geo,device).response { "campaign_id": "camp_456", "group_by": "geo", "data": [ { "geo": "US", "total_clicks": 10000, "unique_clicks": 7500 }, { "geo": "IN", "total_clicks": 5000, "unique_clicks": 3000 } ] }
4.GET /api/v1/fraud/clicks
Description: Retrieves a list of suspected fraudulent click events.
Query Parameters:
ad_id(optional): Filter by ad ID.time_range(optional): e.g.,last_1_hour,last_24_hours.{ "suspicious_clicks": [ { "user_id": "bot_123", "ad_id": "ad_9876", "timestamp": "2024-12-20T12:34:56Z", "geo": "CN", "reason": "High click frequency" } ] }
5.POST /api/v1/campaigns
Creates a new ad campaign.
request
{
"campaign_id": "camp_789",
"name": "Holiday Sale",
"start_date": "2024-12-01",
"end_date": "2024-12-31"
}
response {
"status": "success",
"message": "Campaign created successfully"
}
6.GET /api/v1/campaigns
Description: Fetches all active campaigns.
Query Parameters:
status(optional): e.g.,active,inactive.{ "campaigns": [ { "campaign_id": "camp_456", "name": "Spring Sale", "status": "active" }, { "campaign_id": "camp_789", "name": "Holiday Sale", "status": "inactive" } ] }
7.GET /api/v1/users/{user_id}/activity
Retrieves a user's click activity.
{
"user_id": "12345",
"clicks": [
{
"ad_id": "ad_9876",
"campaign_id": "camp_456",
"timestamp": "2024-12-20T12:34:56Z",
"geo": "US",
"device": "desktop"
}
]
}
Databases
Database Selection
Real-Time Event Storage and Processing:
Database: Apache Kafka (for event streaming).
Purpose: Real-time ingestion and message queue for processing pipelines.
Raw Data Storage:
Database: Amazon S3, HDFS, or Google Cloud Storage.
Purpose: Durable storage of raw click events for long-term analytics.
Aggregated Metrics Storage:
Database:
OLAP Database: ClickHouse, Apache Druid, or Amazon Redshift.
Purpose: Store and query aggregated metrics for dashboards and analytics.
Metadata and Campaign Management:
Database: PostgreSQL, MySQL, or any relational database.
Purpose: Manage campaign metadata, ad information, and user profiles.
Fraud Detection Data:
Database: Redis or MongoDB.
Purpose: Low-latency access for flagged events or fraud-related data.
Database Schema
1. Event Stream (Kafka Topic)
For capturing raw ad click events.
Topic Name:
ad-click-eventsMessage Schema:
{
"event_id": "uuid",
"user_id": "string",
"ad_id": "string",
"campaign_id": "string",
"timestamp": "ISO 8601 format",
"geo": "string",
"device": "string",
"referrer": "string"
}
2. Raw Event Storage (S3/HDFS)
For storing raw click data.
Directory Structure:
/{year}/{month}/{day}/click_events/File Format: Parquet or Avro for efficient storage.
event_id (UUID) user_id (string) ad_id (string) campaign_id (string) timestamp (timestamp) geo (string) device (string) referrer (string)
3. Aggregated Metrics Storage (ClickHouse/Druid/Redshift)
For storing pre-aggregated data for real-time and historical queries.
Table Name:
aggregated_metricsad_id (string) campaign_id (string) geo (string) device (string) time_window (timestamp or interval, e.g., hourly/daily) total_clicks (integer) unique_clicks (integer) ctr (float) Index Composite Index: (campaign_id, ad_id, time_window) for time-based queries. Index on geo and device for demographic/segment filtering.4. Campaign Metadata (PostgreSQL/MySQL)
For managing campaigns, ads, and user metadata.
Table Name:
campaignscampaign_id (string, primary key) name (string) start_date (date) end_date (date) budget (decimal) status (enum: active, inactive)Table Name:
adsad_id (string, primary key) campaign_id (string, foreign key) name (string) media_url (string)
5. Fraud Detection Data (Redis/MongoDB)
For real-time detection and storage of suspicious events.
Collection Name:
fraud_eventsevent_id (UUID) ad_id (string) campaign_id (string) timestamp (timestamp) geo (string) device (string) reason (string, e.g., "bot traffic", "high frequency clicks")
6. User Activity (PostgreSQL or MongoDB)
For querying user-specific click activity.
Table Name:
user_clicksuser_id (string, primary key) ad_id (string) campaign_id (string) timestamp (timestamp) geo (string) device (string)HLD
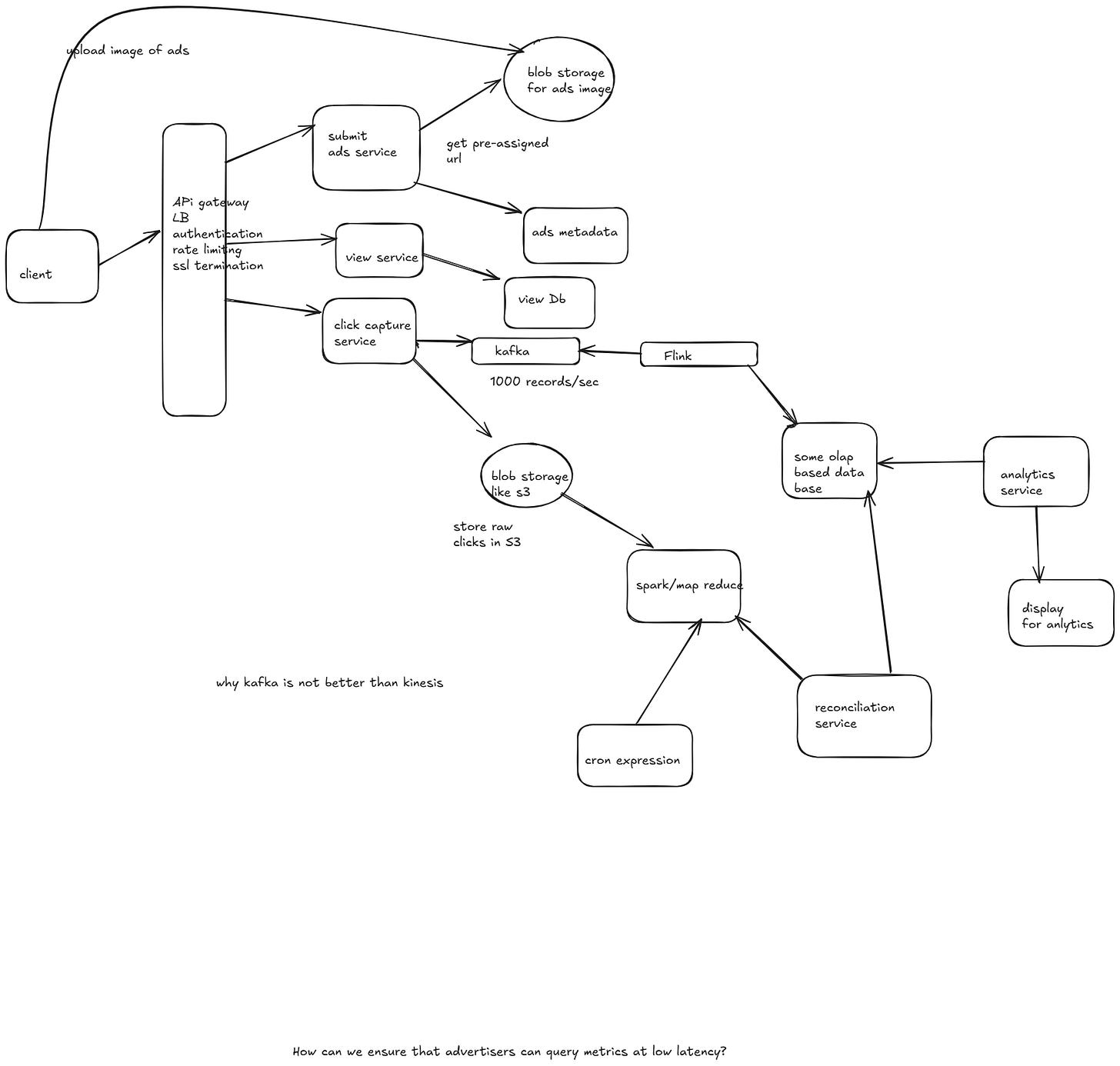
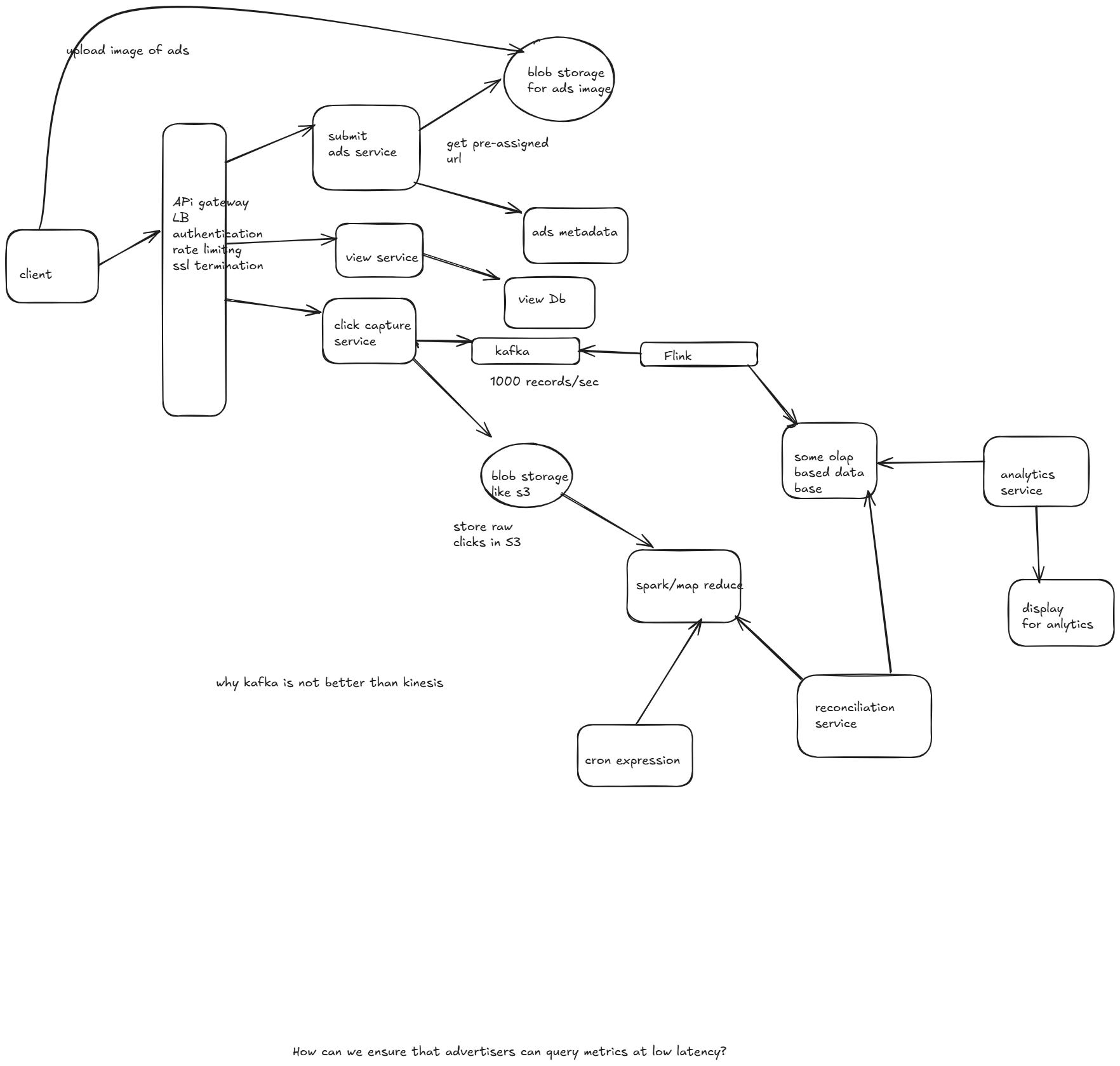
Some open ended questions
Why using flink rather than using spark
for real time updates
Comparison between Flink and Spark
Why Kafka is used inplace of kinesis
Because of low latency