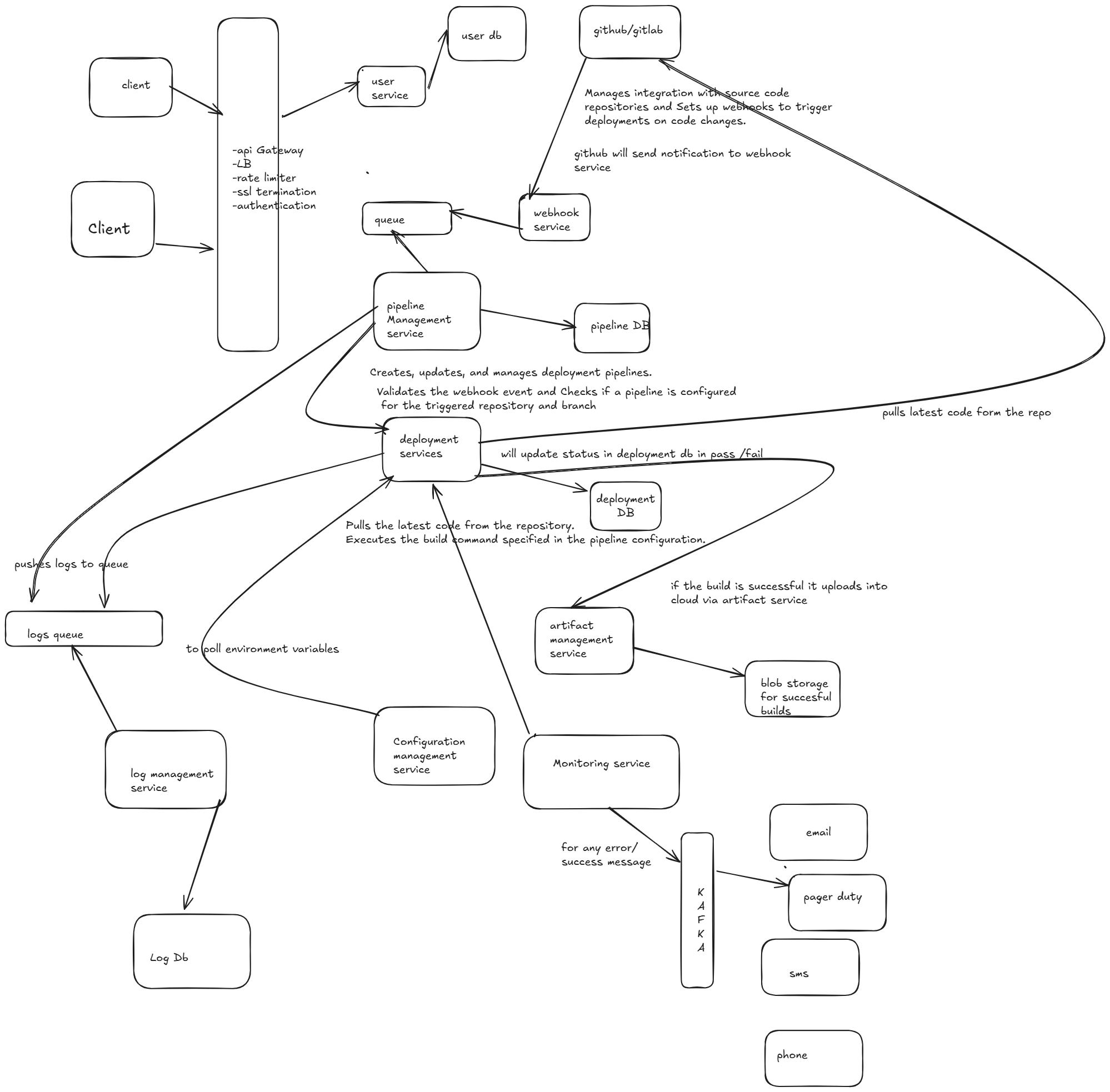
Design code deployment Platform
This design involves understanding how software moves from development to production, with an emphasis on automation, reliability, and scalability.

FR
1. Integrate with popular version control systems (e.g., GitHub, GitLab, Bitbucket).
2. Automatically detect changes in the code repository (e.g., on a pull request or a new commit).
3. Support branch-based deployments (e.g., deploy a specific branch to a staging environment).
4. Automatically trigger builds when new code is pushed to the repository.
5. Enable configuration of build pipelines
for different environments (development, testing, staging, production).
6.Provide a dashboard to monitor build status (success, failure, pending).
7. Automate deployments across multiple environments (dev, staging, production).
8. Centralized management of environment-specific
configuration variables (e.g., secrets, API keys)
9.Support secrets management (integration with tools like HashiCorp Vault, AWS Secrets Manager)
10. Real-time monitoring of deployment progress.
NFR
1.System should be highly scalable to handle a large number of simultaneous deployments across multiple regions.
2.Ensure the platform is highly available with minimal downtime
3.System should be reliable which guarantees that deployments are consistent and resilient to failures.
4.Protect sensitive data and ensure compliance with industry standards.
Estimates
Assume platform serves .1M engineering teams,
each handling 5 microservices on average.
Deployments occur multiple times a day for each service: 2 deployments/day per microservice.
Each deployment process involves build, test, and deployment steps, taking about 15 minutes on average.
We need to store logs, artifacts, and metrics data for 30 days.
Total microservices = .1M teams * 5 microservices = .5M microservices
Deployments per day = .5M microservices * 2 deployments/day = 1M deployments/day
QPS=1M/10^5=10QPSStorage
Daily Data Generated:
We need to store:
1. Build artifacts: Docker images, binaries, etc.
2. Logs: Deployment logs, application logs.
3. Metrics and monitoring data: For tracking deployment performance.
Artifact size per deployment: 200 MB (average Docker image size).
Log size per deployment: 10 MB (build, test, and deployment logs).
Metrics data per deployment: 1 MB.
Artifacts: 1M deployments/day * 200 MB = 200TB/day
Logs: 1M deployments/day * 10 MB = 10TB/day
Metrics: 1M deployments/day * 1 MB = 1 TB/day
Calculation for 30 days
Artifacts: 200 TB/day * 30 days = 6000 TB
Logs: 10 GB/day * 30 days = 300 TB
Metrics: 1 GB/day * 30 days = 30 GB
Total storage requirement = 6000+300+30=6330 TBThe average microservice uses a Docker container with 1 CPU core and 2 GB RAM during build and deployment.
The organization uses cloud infrastructure (e.g., AWS, GCP, or Azure).
API’s
1. POST /api/v1/auth/login
Authenticate a user and issue a token
user _id as jwt token
Request Body:
{
"username": "john_doe",
"password": "your_password"
}
Response:
{
"token": "jwt_token",
"expires_in": 3600
}
2. POST /api/v1/repos/connect
Connect a code repository (e.g., GitHub, GitLab).
{
"repo_url": "https://github.com/org/repo",
"branch": "main",
"scm_type": "github",
"webhook_secret": "secret_key"
}3. POST /api/v1/repos/webhook
Webhook endpoint to trigger deployments on new commits or pull requests.
4. GET /api/v1/pipelines
List all deployment pipelines.
5.POST /api/v1/pipelines
Create a new deployment pipeline.
Request Body:
{
"name": "production-pipeline",
"repo_id": "repo123",
"branch": "main",
"build_command": "mvn clean package",
"deploy_strategy": "blue-green"
}6. PUT /api/v1/pipelines/{pipelineId}
Update pipeline settings.
7. DELETE /api/v1/pipelines/{pipelineId}
Delete a deployment pipeline.
8.POST /api/v1/deployments
Trigger a deployment manually.
{
"pipeline_id": "pipeline123",
"commit_hash": "abc123def",
"environment": "staging",
"config_overrides": {
"env": "staging",
"db_host": "staging-db.example.com"
}
}9.GET /api/v1/artifacts
List all stored artifacts.
POST /api/v1/artifacts/upload
Upload a new artifact.
Request Body:
{
"pipeline_id": "pipeline123",
"artifact": "binary_file",
"version": "v1.0.0"
}11.GET /api/v1/artifacts/{artifactId}
Download a specific artifact.
12.DELETE /api/v1/artifacts/{artifactId}
Delete an old artifact.
GET /api/v1/configs/{environment}
Get configuration variables for a specific environment.
POST /api/v1/configs/{environment}
Add or update configuration variables.
Request Body:
{
"db_password": "new_password",
"api_key": "12345"
}GET /api/v1/monitoring/metrics
Retrieve metrics (CPU, memory, etc.) for deployments.
GET /api/v1/logs/{deploymentId}
Fetch logs for a specific deployment.
GET /api/v1/logs/search
Search logs with filters (e.g., error logs).
Query Parameters:
{
"pipeline_id": "pipeline123",
"log_level": "ERROR",
"start_time": "2024-11-01T00:00:00Z",
"end_time": "2024-11-07T23:59:59Z"
}
DataBase Schema
1. Users Table
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
role VARCHAR(20) CHECK (role IN ('admin', 'developer', 'viewer')),
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_users_username ON users (username);
2. Repositories Table
CREATE TABLE repositories (
repo_id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
repo_url VARCHAR(255) UNIQUE NOT NULL,
branch VARCHAR(50) DEFAULT 'main',
scm_type VARCHAR(20) CHECK (scm_type IN ('github', 'gitlab', 'bitbucket')),
webhook_secret VARCHAR(100),
user_id INT REFERENCES users(user_id) ON DELETE SET NULL,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_repositories_user_id ON repositories (user_id);
3. Pipelines Table
CREATE TABLE pipelines (
pipeline_id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
repo_id INT REFERENCES repositories(repo_id) ON DELETE CASCADE,
branch VARCHAR(50),
build_command TEXT,
deploy_strategy VARCHAR(20) CHECK (deploy_strategy IN ('blue-green', 'canary', 'rolling')),
environment VARCHAR(20) DEFAULT 'development',
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_pipelines_repo_id ON pipelines (repo_id);
4. Deployments Table
CREATE TABLE deployments (
deployment_id SERIAL PRIMARY KEY,
pipeline_id INT REFERENCES pipelines(pipeline_id) ON DELETE CASCADE,
commit_hash VARCHAR(40),
status VARCHAR(20) CHECK (status IN ('pending', 'in_progress', 'success', 'failed', 'rolled_back')),
environment VARCHAR(20),
start_time TIMESTAMP,
end_time TIMESTAMP,
triggered_by INT REFERENCES users(user_id),
rollback_of INT REFERENCES deployments(deployment_id),
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_deployments_pipeline_id ON deployments (pipeline_id);
CREATE INDEX idx_deployments_status ON deployments (status);
5. Artifacts Table
CREATE TABLE artifacts (
artifact_id SERIAL PRIMARY KEY,
pipeline_id INT REFERENCES pipelines(pipeline_id) ON DELETE CASCADE,
version VARCHAR(50),
artifact_path VARCHAR(255),
size_in_mb DECIMAL(10, 2),
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_artifacts_pipeline_id ON artifacts (pipeline_id);
6. Configurations Table
CREATE TABLE configurations (
config_id SERIAL PRIMARY KEY,
environment VARCHAR(20),
key VARCHAR(100) NOT NULL,
value TEXT NOT NULL,
is_secret BOOLEAN DEFAULT FALSE,
pipeline_id INT REFERENCES pipelines(pipeline_id) ON DELETE CASCADE,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW(),
UNIQUE (pipeline_id, environment, key)
);
7. Logs Table
CREATE TABLE logs (
log_id SERIAL PRIMARY KEY,
deployment_id INT REFERENCES deployments(deployment_id) ON DELETE CASCADE,
log_level VARCHAR(20) CHECK (log_level IN ('INFO', 'WARNING', 'ERROR', 'DEBUG')),
message TEXT,
timestamp TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_logs_deployment_id ON logs (deployment_id);
CREATE INDEX idx_logs_log_level ON logs (log_level);
8. Notifications Table
CREATE TABLE notifications (
notification_id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(user_id) ON DELETE CASCADE,
type VARCHAR(20) CHECK (type IN ('email', 'slack')),
target VARCHAR(255),
events TEXT[], -- Array of events like ['deployment_success', 'deployment_failure']
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_notifications_user_id ON notifications (user_id);
9. Audit Logs Table
CREATE TABLE audit_logs (
audit_id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(user_id) ON DELETE SET NULL,
action VARCHAR(100),
details TEXT,
timestamp TIMESTAMP DEFAULT NOW()
);
CREATE INDEX idx_audit_logs_user_id ON audit_logs (user_id);
Relationships Summary
Users can create repositories, manage pipelines, trigger deployments, and receive notifications.
Repositories are linked to pipelines, which define the build and deployment strategies.
Deployments track each release triggered by a pipeline and are linked to artifacts and logs.
Configurations store environment variables and secrets used during the build and deployment process.
Logs capture deployment activities, and audit logs keep track of user actions for security and compliance.
Indexes and OptimizationsIndexes are created on foreign keys and frequently queried columns (e.g.,
status,log_level).Unique constraints are used where appropriate (e.g., configurations for a specific environment).
Tables like logs and audit_logs can be partitioned or stored in separate databases for scalability if needed.
Scaling ConsiderationsSharding can be applied to tables like
deployments,logs, andartifactsbased on thepipeline_idorenvironmentto distribute load.For high write throughput (especially in
logsanddeployments), consider using NoSQL databases like Elasticsearch for logs or Cassandra for deployments if scalability becomes an issue.Implement caching for frequently accessed data (e.g.,
pipelinesandrepositories) using Redis or Memcached.
HLD