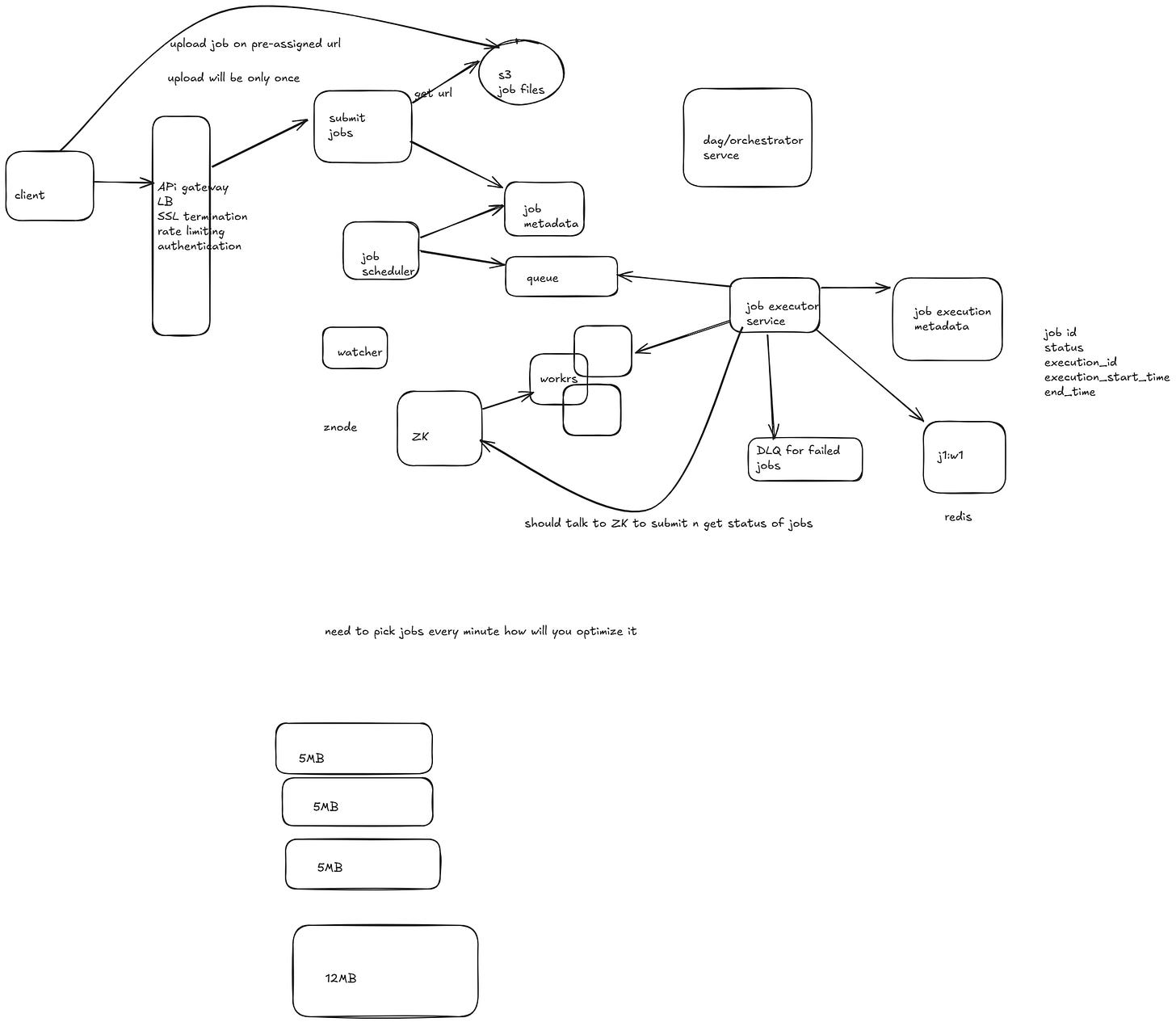
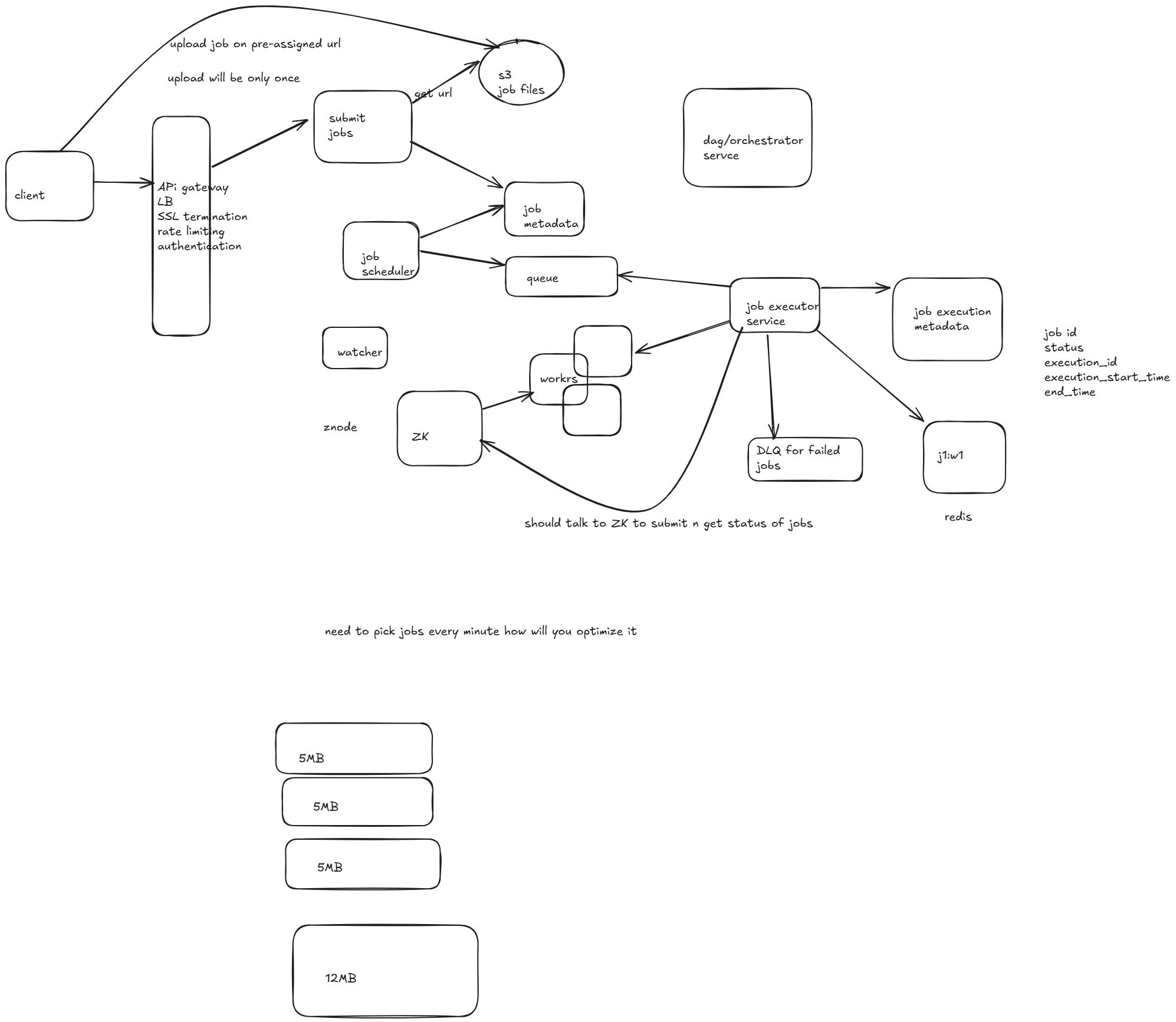
Design Distributed Job Scheduler
Let's start with Functional Requirements

FR
1.Users should be able to submit jobs to the system with necessary configurations (e.g., execution time, priority, type of job).
2.Jobs should be queued and processed based on defined scheduling policies (e.g., priority, FIFO, fair scheduling).
3.The system should support both one-time execution, recurring style
4.The system should have the capability to support a retry feature
5.Allow defining dependencies between jobs (e.g., Job B runs only after Job A completes).
6.Allow modifications to scheduled jobs (e.g., rescheduling or updating parameters).
7.Provide real-time status updates for jobs (e.g., queued, running, completed, failed).
NFR
1.The system should efficiently handle increasing job load by adding more worker or scheduler nodes, thereby making it highly scalable
2.Ability to process and execute a large number of jobs concurrently without significant degradation in performance.
3.System should be fault tolreant to handle failures (e.g., node crashes or network issues) and ensure job execution continuity.
4.System should be highly available to maintain 99.99% uptime, ensuring the system is available for scheduling and managing jobs at all times.
5.system should be highly durable to ensure that submitted jobs are not lost due to system failures .
6.Minimize the time taken to schedule a job after it is submitted.(low latency)
7.Guarantee consistency in job status (e.g., queued, running, completed) across distributed components.(strict consistency)
8.In cases where strict consistency is relaxed, ensure eventual consistency of job states in distributed systems.
Estimates
Assume 100M jobs per day
Number of jobs per sec=100M/10^5=1k jobs/sec(write QPS)
Average job metadata size: 1 KB per job (includes job ID, parameters, status, etc.).
Job retention: Keep job metadata for 30 days.
Retry policy: Each job may fail and retry twice on average.
Here write qps will change 2*1kQPS=2k QPS
Workers: Assume 100 worker nodes.
Latency: Jobs must be scheduled within 10 milliseconds.Storage=100M*1KB=100GB/day*30=3kGB/month*12=36k GB for one year
API’s
1.POST api/v1/jobs
request {
"job_id": "string",
"job_type": "string",
"schedule_time": "timestamp",
"priority": "high/medium/low",
"payload": { "key": "value" }
}
response
{
"status": "submitted",
"job_id": "string"
}
2.PUT api/v1/jobs/{job_id}
Update the schedule or parameters of an existing job.
request {
"schedule_time": "timestamp",
"priority": "high/medium/low",
"payload": { "key": "updated_value" }
}
response
{
"status": "updated",
"job_id": "string"
}
3.DELETE api/v1/jobs/{job_id}
reponse {
"status": "cancelled",
"job_id": "string"
}
4.GET api/v1/jobs/{job_id}
Fetch the current status of a job.
reponse {
"job_id": "string",
"status": "queued/running/completed/failed",
"start_time": "timestamp",
"end_time": "timestamp",
"retries": 2
}
GET api/v1 /jobs?status=completed&job_type=data_processing&start_time=2024-12-17T00:00:00Z
[ { "job_id": "string", "status": "queued", "schedule_time": "timestamp" }, { "job_id": "string", "status": "completed", "schedule_time": "timestamp" } ]Databases
1. Databases to be Used:
Relational Database (RDBMS) (e.g., PostgreSQL, MySQL):
Use Case: If the system needs ACID guarantees for job submissions, updates, retries, and status tracking with complex querying requirements (e.g., filtering by job status, type, or schedule time).
Examples: PostgreSQL, MySQL, MariaDB.
Jobs Table job_id (UUID): A unique identifier for each job. status (VARCHAR): The current status of the job (e.g., queued, running, completed, failed). job_type (VARCHAR): Type of the job (e.g., data_processing, report_generation). schedule_time (TIMESTAMP): When the job was scheduled. start_time (TIMESTAMP): When the job started execution (nullable). end_time (TIMESTAMP): When the job completed or failed (nullable). payload (JSONB): The job's data (input parameters, etc.). retry_count (INT): The number of times the job has been retried. last_updated (TIMESTAMP): The last time the job's status was updated.Jobs log table
log_id (UUID): A unique identifier for each log entry. job_id (UUID, Foreign Key to jobs): A reference to the job. log_message (TEXT): A message describing the job's execution. log_level (VARCHAR): The severity level of the log (INFO, ERROR). log_time (TIMESTAMP): When the log was generated.Job retry table
retry_id (UUID): A unique identifier for each retry attempt. job_id (UUID, Foreign Key to jobs): A reference to the job. retry_time (TIMESTAMP): When the retry was attempted. status (VARCHAR): The current status of the retry (queued, in_progress, completed, failed).
NoSQL Database (e.g., MongoDB, Cassandra):
Use Case: For large-scale distributed systems with high write throughput and less complex querying requirements (i.e., quick access to jobs and metadata).
Examples: MongoDB (for document storage), Cassandra (for time-series and wide-column store).
{ "_id": ObjectId("..."), "job_id": "1", "status": "queued", "job_type": "data_processing", "schedule_time": ISODate("2024-12-18T10:00:00Z"), "start_time": ISODate("2024-12-18T10:10:00Z"), "end_time": ISODate("2024-12-18T10:15:00Z"), "payload": { "data": "value" }, "retry_count": 1, "last_updated": ISODate("2024-12-18T10:15:00Z"), "logs": [ { "log_time": ISODate("2024-12-18T10:10:00Z"), "log_message": "Job started" }, { "log_time": ISODate("2024-12-18T10:15:00Z"), "log_message": "Job completed" } ], "retries": [ { "retry_time": ISODate("2024-12-18T10:05:00Z"), "status": "in_progress" } ] }
In-Memory Database (e.g., Redis):
Use Case: For storing transient job state information, job retries, and caching frequently queried data to improve performance. Redis could also be used for fast job scheduling and queuing.
Examples: Redis (for caching and fast job queuing).
Redis can store jobs in different states (e.g., queued, in-progress) as sets or sorted sets for fast job scheduling.
Queue for pending jobs:
queued_jobsQueue for in-progress jobs:
in_progress_jobsQueue for completed jobs:
completed_jobs
Job data can be stored as serialized JSON objects or simple references to the job records in the main database.
Example (Storing job in Redis):
SET job:1 {"job_id": "1", "status": "queued", "schedule_time": "2024-12-18T10:00:00Z"}