
Design distributed job Scheduler
A distributed job scheduler manages and executes jobs across multiple nodes efficiently.

FR
1.Users should be able to submit one-time or recurring jobs.
2.Jobs can be delayed or scheduled at a specific time.
3.Support High, Medium, Low priority queues.
4.Support parallel job execution across multiple workers.
5.If a worker crashes, jobs should be rescheduled to another available worker.
6.Jobs should support dependencies (e.g., Job B runs only after Job A completes).
7.Users should be able to query job status (RUNNING, FAILED, COMPLETED).
8.Notify users (via email, Webhook, Kafka) upon job completion/failure.
9.Ensure that duplicate jobs are not scheduled accidentally.(idempotency should be taken care of)
NFR
1.Jobs should be picked up within milliseconds of their scheduled time.
2.P99 latency should be < 50ms for job assignment.
3. System should be highly scalable to handle more jobs (more worker nodes = more jobs processed).
4.The scheduler should be highly available (99.99% uptime).
5.Job status should be eventually consistent across distributed nodes.
Estimates
Total jobs per day = 10M jobs
QPS=10M/10^5=100QPS
Peak traffic (requests per second) = ~200 jobs/sec (assuming peak 6 hours/day)
Job size (metadata per job) = 1KB (includes ID, status, timestamps, etc.)
Job execution time = 500ms per job (on average)
Retention period = 30 days (job history kept in DB)
Job Failure Rate = 5% (500K jobs need retries)
Database replication factor = 3 (for HA)
Cache hit rate = 95% (Redis for job metadata)Storage
Job metadata= 1KB
total storage=10M*1KB=10GB per day
Retention period for 30 days=10GB*30=300GB
Replication factor (3x) for durable storage=300GB*3=900GBAPI’s
1.POST /api/v1/jobs
request {
"jobName": "Data Processing Job",
"jobType": "batch",
"command": "python process.py",
"artifact_type":docker_image/s3link/zip_file
"schedule": "0 0 * * *",
"priority": "HIGH",
"maxRetries": 3,
"timeoutSeconds": 300,
"payload": {
"inputFile": "s3://bucket/input.csv",
"outputFile": "s3://bucket/output.csv"
}
dependency_jobs:list of job ids
}
response {
"jobId": "12345",
"status": "PENDING"
}
2.GET /api/v1/jobs/{jobId}
{
"jobId": "12345",
"status": "RUNNING",
"createdAt": "2025-02-19T10:00:00Z",
"nextRunAt": "2025-02-20T00:00:00Z",
"retries": 1,
"logs": "Executing task..."
}
3.GET /api/v1/jobs?status=RUNNING&limit=10
{
"jobs": [
{ "jobId": "12345", "status": "RUNNING", "schedule": "0 0 * * *" },
{ "jobId": "67890", "status": "PENDING", "schedule": "*/5 * * * *" }
]
}
4.DELETE /api/v1/jobs/{jobId}
{
"jobId": "12345",
"status": "CANCELLED"
}
5.POST /api/v1/workers/pick-job
resposne {
"jobId": "12345",
"command": "python process.py",
"payload": { "inputFile": "s3://bucket/input.csv" }
}
6.POST /api/v1/jobs/{jobId}/status
request {
"status": "COMPLETED",
"executionTimeMs": 4500,
"logs": "Job executed successfully."
}
resposne { "message": "Job status updated successfully." }
7.GET /api/v1/metrics/jobs
{
"totalJobs": 100000,
"completedJobs": 95000,
"failedJobs": 5000,
"avgExecutionTimeMs": 3500
}
8.GET /api/v1/metrics/workers
{
"totalWorkers": 100,
"activeWorkers": 95,
"idleWorkers": 5,
"avgWorkerLoad": 80
}
9.POST /api/v1/workers/register
request {
"workerId": "worker-123",
"capacity": 10,
"cpuUsage": 20,
"memoryUsage": 50
}
response { "message": "Worker registered successfully." }
Databases for a Distributed Job Scheduler & Their Schema
A distributed job scheduler requires different types of databases for various components based on performance, scalability, and consistency needs.
🔹 Stores job metadata, execution history, and scheduling information.
🔹 Ensures ACID compliance for job transactions.
🔹 Good for complex queries (filtering, sorting, pagination).
Schema for Relational DB (PostgreSQL/MySQL)
jobs Table (Stores Job Metadata)
CREATE TABLE jobs (
job_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
job_name VARCHAR(255) NOT NULL,
job_type ENUM('one-time', 'recurring', 'batch') NOT NULL,
schedule VARCHAR(255) NULL, -- cron expression
command TEXT NOT NULL,
status ENUM('PENDING', 'RUNNING', 'COMPLETED', 'FAILED', 'CANCELLED') NOT NULL DEFAULT 'PENDING',
priority ENUM('LOW', 'MEDIUM', 'HIGH') DEFAULT 'MEDIUM',
max_retries INT DEFAULT 3,
timeout_seconds INT DEFAULT 300,
created_at TIMESTAMP DEFAULT NOW(),
updated_at TIMESTAMP DEFAULT NOW()
);
job_executions Table (Stores Execution Logs)
CREATE TABLE job_executions (
execution_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
job_id UUID REFERENCES jobs(job_id) ON DELETE CASCADE,
worker_id VARCHAR(255) NOT NULL,
status ENUM('RUNNING', 'COMPLETED', 'FAILED', 'RETRYING') NOT NULL DEFAULT 'RUNNING',
execution_time_ms INT,
logs TEXT,
started_at TIMESTAMP DEFAULT NOW(),
completed_at TIMESTAMP
);
2️⃣ NoSQL Database (Cassandra/DynamoDB) → Fast Job Lookup & History
🔹 Used for fast retrieval of job status and execution history.
🔹 High write scalability (handles millions of updates).
🔹 Schema-less flexibility.
Schema for NoSQL DB (Cassandra)
jobs_by_status Table (For Quick Lookup)
CREATE TABLE jobs_by_status (
status TEXT,
job_id UUID,
job_name TEXT,
created_at TIMESTAMP,
PRIMARY KEY (status, created_at, job_id)
) WITH CLUSTERING ORDER BY (created_at DESC);
SELECT * FROM jobs_by_status WHERE status = 'RUNNING' LIMIT 100;
job_execution_logs Table (For Fast Job History Retrieval)
CREATE TABLE job_execution_logs (
job_id UUID,
execution_id UUID,
status TEXT,
logs TEXT,
execution_time_ms INT,
completed_at TIMESTAMP,
PRIMARY KEY (job_id, completed_at)
) WITH CLUSTERING ORDER BY (completed_at DESC);
3️⃣ In-Memory Database (Redis) → Fast Job Scheduling & Worker Queues
🔹 Low-latency job scheduling and job dispatching.
🔹 Used as a distributed queue for assigning jobs to workers.
Schema for Redis
Redis Sorted Set for Job Prioritization
ZADD job_queue 10 "job_12345"
ZADD job_queue 20 "job_67890" # Higher priority job
👉 Workers fetch jobs using:
ZRANGE job_queue 0 0 WITHSCORES
👉 Remove from queue after execution:
ZREM job_queue "job_12345"
4️⃣ Distributed Object Storage (S3/MinIO) → Job Execution Logs & Artifacts
🔹 Stores large job logs, execution artifacts, and input/output files.
🔹 Used for batch processing jobs.
S3 Bucket Structure
/job-logs/
├── job_12345/
├── execution_1.log
├── execution_2.log
├── job_67890/
├── execution_1.log
5️⃣ Time-Series Database (Prometheus/TimescaleDB) → Job Metrics & Monitoring
🔹 Stores execution time, job success rate, worker health metrics.
🔹 Optimized for time-series data.
Schema for Prometheus Metrics
Job Execution Duration
job_execution_duration_seconds{job_id="12345", status="COMPLETED"} 4.5
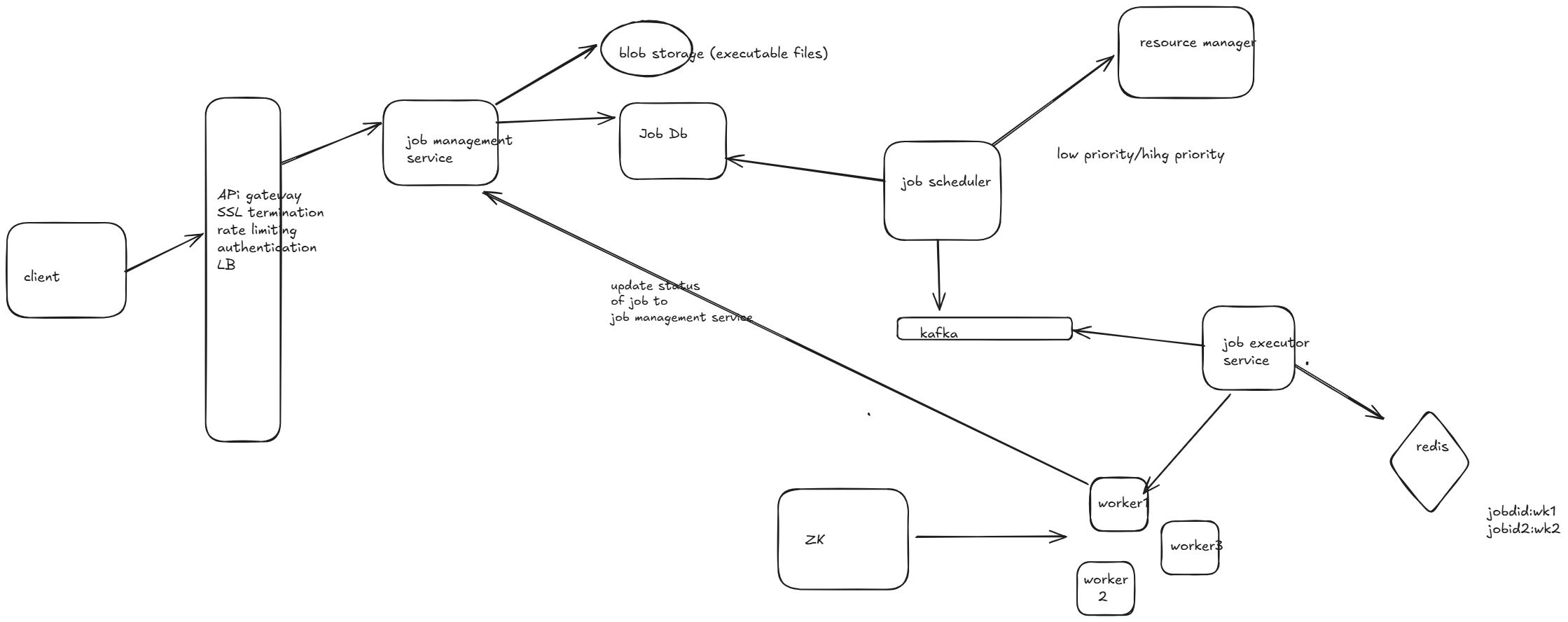
HLD
Below is a high-level flow of interactions between microservices:
User submits a job →
Job Management ServiceJob is added to queue →
Queue Management Service(Redis/Kafka)Worker picks up job →
Job Execution Serviceassigns itWorker executes job →
Worker Node ServiceWorker updates status → Reports to
Job Execution ServiceJob result is stored →
Job Management Serviceupdates DBMetrics are tracked →
Monitoring & Metrics Servicelogs performanceNotifications are sent →
Notification Serviceinforms users
How to Ensure Jobs Are Not Duplicated in a Distributed Job Scheduler
When running a distributed job scheduler with multiple worker nodes, job duplication can occur due to network failures, retries, or concurrent processing. Below are key strategies to ensure exactly-once execution or idempotency to prevent job duplication.
1️⃣ Deduplication Strategies
1. Unique Job ID with Idempotency Check (Database or Cache)
✅ Ensure each job has a unique job_id stored in a database or Redis.
✅ Before executing, check if the job has already been processed.
✅ If job_id exists with status=COMPLETED, reject reprocessing.
2. Distributed Locks (Redis/Zookeeper)
✅ Use Redis SETNX (Set if Not Exists) + Expiry to lock jobs.
✅ Ensures that only one worker picks up a job at a time.
3. Exactly-Once Processing Using Kafka (Message Queues)
✅ If jobs are scheduled via Kafka, use Kafka Consumer Groups.
✅ Kafka ensures each partition is processed by only one consumer.
✅ Use offset commits to mark jobs as processed.
4. Transactional Job Updates in Database
✅ Use atomic transactions in MySQL/PostgreSQL.
✅ Insert job execution record with a unique constraint on job_id.
✅ If duplicate job submission occurs, the transaction fails.
5. Leader Election (Zookeeper/Etcd)
✅ Elect one leader node responsible for job assignment.
✅ Leader ensures no duplicate job allocation to multiple workers.
📌 Using Zookeeper for Leader Election:
Fault-Tolerant Recovery Mechanisms for Failed Jobs
Ensuring that failed jobs are retried correctly while avoiding duplicates and maintaining consistency is crucial in a distributed job scheduler. Below are key strategies for handling failures and ensuring fault tolerance.
1️⃣ Failure Handling & Recovery Strategies
1. Job Status Tracking in Database
✅ Store job execution status (PENDING, RUNNING, FAILED, COMPLETED).
✅ Failed jobs are retried only if their status is FAILED.
📌 Schema Example:
CREATE TABLE job_executions (
job_id UUID PRIMARY KEY,
status ENUM('PENDING', 'RUNNING', 'FAILED', 'COMPLETED'),
retry_count INT DEFAULT 0,
updated_at TIMESTAMP DEFAULT NOW()
);
📌 Atomic Update on Failure:
UPDATE job_executions
SET status = 'FAILED', retry_count = retry_count + 1
WHERE job_id = 'job_12345';
2. Retry Mechanism with Exponential Backoff
✅ Instead of retrying immediately, use delayed retries with exponential backoff.
✅ Helps avoid overloading the system with retries.
📌 Retry Delays (Exponential Backoff Formula)
Delay = min(initialDelay * (2 ^ retryCount), maxDelay)
3. Dead Letter Queue (DLQ) for Permanent Failures
✅ If a job fails after N retries, move it to a Dead Letter Queue (DLQ).
✅ Prevents stuck jobs from blocking new ones.
📌 Using Kafka DLQ
If a worker fails after 3 retries, push to DLQ:
4. Distributed Locks to Avoid Duplicate Retries
✅ Before retrying, check if another worker has already picked up the job.
✅ Use Redis Locks or Zookeeper Locks.
📌 Redis Lock to Prevent Duplicate Retries:
5. Worker Heartbeat & Failover Mechanism
✅ Workers send a heartbeat signal every few seconds.
✅ If a worker crashes mid-job, the job is reassigned.
📌 Using Redis for Worker Heartbeat Check:
6. Leader Election for Job Reassignment
✅ If a worker crashes, the leader node detects failure & reassigns jobs.
✅ Use Zookeeper or Etcd to elect a leader.
📌 Zookeeper-Based Leader Election:
7. Monitoring & Alerting for Failed Jobs
✅ Log all failures and trigger alerts for failures beyond a threshold.
✅ Use Prometheus + Grafana for monitoring job failures.