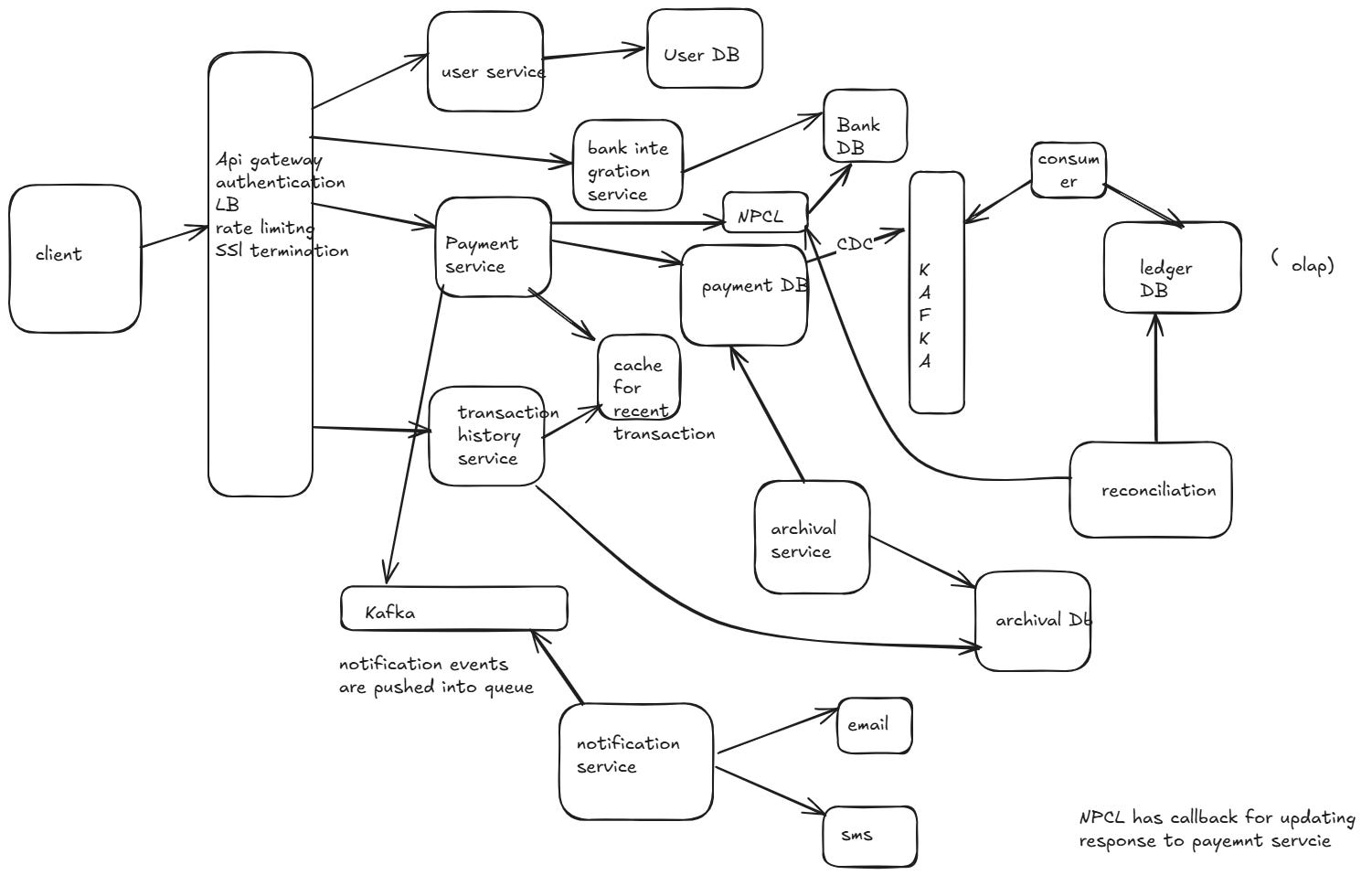
Design UPI payment app like Google Pay
For designing a UPI payment app, here’s a structured approach to your problem:

FR
1.Send and receive payments using UPI ID, phone number, or bank details (IFSC).
2. Real-time transaction updates and payment confirmation.
3.Handle edge cases like failures or retries.
4.Retrieve all payment history (sent and received) for a user.(How to fecth billions of transactions from DB)
5.Fetch P2P history between specific users (e.g., User A & User B).
6.Ensure low-latency query responses for history retrieval.
7.Notify users about the payment
8.Payment should be idempotent in nature
9.After x number of payments need to show scratch card
NFR
1.System should be highly scalable to handle payment for large number of transactions(100M transactions everyday)
2.Ensure availability and fault tolerance.???
3.System should be highly consistent while performing transactions
4.Secure sensitive data like UPI IDs and transaction details.
5.Prevent unauthorized access to transaction history.
API’s
POST api/v1/users
request { "name": "John Doe", "phoneNumber": "+919876543210", "upiId": "john@upi" } response { "userId": "user_12345", "message": "User registered successfully." }2. POST api/v1/bank
request { bank_name:"abc bank", acc_no:9083838838383,IFSC :HDFC3332} response{"message":"bank added successfully"}GET api/v1/users/{userId}
{ "userId": "user_12345", "name": "John Doe", "phoneNumber": "+919876543210", "upiId": "john@upi" }POST api/v1/paymentsStarts a P2P payment between users.
request {
"fromUserId": "user_12345",
"toUserId": "user_67890",
"amount": 500,
"mode": "UPI", // or "Phone", "BankIFSC"
"message": "Payment for dinner"
}
response {
"transactionId": "txn_98765",
"status": "Processing"
}
4.GET api/v1/payments/{transactionId}/status
Check the current status of a specific payment.
{
"transactionId": "txn_98765",
"status": "Success",
"timestamp": "2024-12-27T12:00:00Z"
}
5.GET api/v1/users/{userId}/transactions
Fetch all transactions (sent and received) for a specific user.
Query Params:
?page=1&pageSize=50&startDate=2024-12-01&endDate=2024-12-27{ "transactions": [ { "transactionId": "txn_123", "type": "Sent", "toUserId": "user_67890", "amount": 500, "status": "Success", "timestamp": "2024-12-26T10:00:00Z" }, { "transactionId": "txn_124", "type": "Received", "fromUserId": "user_67890", "amount": 1000, "status": "Success", "timestamp": "2024-12-26T15:00:00Z" } ], "page": 1, "totalPages": 60 }6.GET api/v1/users/{userId}/transactions/p2pFetch transaction history between two specific users.
Query Params:
?peerUserId=user_67890&page=1&pageSize=20{ "transactions": [ { "transactionId": "txn_123", "type": "Sent", "toUserId": "user_67890", "amount": 500, "status": "Success", "timestamp": "2024-12-26T10:00:00Z" }, { "transactionId": "txn_124", "type": "Received", "fromUserId": "user_67890", "amount": 300, "status": "Success", "timestamp": "2024-12-25T20:00:00Z" } ], "page": 1, "totalPages": 5 }POST api/v1/notifications
request { "userId": "user_67890", "message": "You have received ₹500 from John Doe." } response { "userId": "user_67890", "message": "You have received ₹500 from John Doe." }GET api/v1/users/{userId}/summary
request { "totalSent": 5000, "totalReceived": 8000, "transactionsCount": 20 }GET /users/{userId}/summary/peer
Fetch statistics of transactions with a specific peer.
Query Params:
?peerUserId=user_67890{ "totalSentToPeer": 2500, "totalReceivedFromPeer": 1500, "transactionsCountWithPeer": 5 }
Estimates
Traffic estimates
Daily Transactions (DAU): 100M transactions/day.
Monthly Transactions: ≈3B transactions/month.
Average Transaction Size: 500 bytes per transaction (including metadata like user IDs, timestamps, amount, status, etc.).
Duplication: Each transaction is stored for both the sender and receiver.
Total entries = 2 × number of transactions.
Peak Hours: Assume 20% of traffic occurs during peak hours (3 hours/day).
20% of 100M = 20M peak-hour transactions.write TPS= 100M/10^5=1k TPS
since each transaction is doubled so 2*1 k TPS=2k TPSRead QPS= 10% of 100M=10M
Each user will do 2 queries per sec=2*10M=20M
read QPS=20M/10^5=200 QPSTransaction Size: 500 bytes (with metadata).
Daily Transactions: 100M.
Data Duplication: 2x (one for sender and one for receiver).
Daily Storage= 100M*500bytes=5KB *10M*2(for sender and reciever) =100 GB
per months= 100GB*30=3000GB
for year=12*3000GB=36000GB=36TB/year
Databases
Secondary Index and Search
Elasticsearch or OpenSearch:
For enabling fast searches, like finding P2P transactions between User A and User B.
Used for filtering and querying transaction data efficiently.
Caching Layer
Redis or Memcached:
For storing frequently accessed data, such as recent transaction history.
Cold Storage for Archival Data
Object Storage:
Options: Amazon S3, Google Cloud Storage, or Azure Blob Storage.
For storing old transactions that are rarely accessed but must be retained (e.g., for compliance).
Table Name: Transactions
Partition Key: UserID (shards transactions by user)
Clustering Key: Timestamp (orders transactions for each user by time)
Columns:
- TransactionID (Unique ID for the transaction)
- CounterpartyID (Other party in the transaction)
- Amount (Transaction amount)
- Type (Sent or Received)
- Status (Success, Failed, Pending)
- Metadata (Optional: Payment message, tags, etc.)
- Timestamp (When the transaction occurred)
Get all transactions for user A
SELECT * FROM Transactions WHERE UserID = 'user_12345' ORDER BY Timestamp DESC;
Duplicate Transactions for Sender and Receiver
Each transaction is duplicated to optimize reads (avoiding cross-shard queries).
For User A (Sender): Stored as "Sent."
For User B (Receiver): Stored as "Received."
P2P Transactions Table (Optional)
For fast lookup of transactions between two users, precompute and store P2P transactions in a separate table.
Table Name: P2PTransactions
Partition Key: UserID (one user of the pair)
Clustering Key: CounterpartyID + Timestamp
Columns:
- TransactionID
- CounterpartyID
- Amount
- Type
- Status
- Metadata
- Timestamp
Get all transactions between User A and User B
SELECT * FROM P2PTransactions
WHERE UserID = 'user_12345' AND CounterpartyID = 'user_67890' ORDER BY Timestamp DESC;
To store user-related information like phone numbers and UPI IDs.
Table Name: Users
Primary Key: UserID
Columns:
- UserID (Unique identifier for the user)
- Name (User's name)
- PhoneNumber
- UPIID
- CreatedAt (Timestamp when the user was registered)
For compliance and debugging purposes, store detailed logs of each transaction
Table Name: AuditLogs Partition Key: TransactionID Columns: - TransactionID - UserID - CounterpartyID - Event (e.g., "Initiated", "Success", "Failed") - Metadata - TimestampCaching Recent Transactions
Schema for Redis Cache:
Key:
user:{userId}:transactionsValue: A list of recent transactions (e.g., last 50 transactions).
Key: user:12345:transactions Value: [ { "txnId": "txn_1", "amount": 500, "type": "Sent", "timestamp": "2024-12-26T10:00:00Z" }, { "txnId": "txn_2", "amount": 1000, "type": "Received", "timestamp": "2024-12-26T15:00:00Z" } ]
Using SQL databases for the UPI Payment App design is feasible but comes with certain trade-offs given the scale of operations (100M transactions per day). Below, I'll discuss why SQL databases may not be the optimal choice for the entire system and where they might still be applicable.
Challenges with Using SQL Databases
1. Write Scalability:
High Write Throughput: At 100M transactions/day (≈37000 peak writes/sec), SQL databases like MySQL or PostgreSQL struggle to handle such high write throughput at scale. They are not inherently designed for horizontal scalability (sharding requires manual configuration and management).
Replication Overhead: SQL databases use leader-follower replication for durability and high availability, which can introduce significant write latency as replicas need to catch up.
2. Read Scalability:
Transaction History Queries: Fetching user transaction history (all transactions and P2P history) involves billions of rows. SQL databases can struggle with such queries, especially if the data grows beyond what a single server can handle.
Indexing Overhead: For fast reads, SQL databases require indexing, which increases storage and slows down writes as indexes need to be updated for every transaction.
3. Sharding Complexity:
SQL databases can be sharded manually (e.g., based on user ID), but this adds significant operational complexity:
Managing distributed transactions.
Handling cross-shard queries (e.g., P2P transactions between users in different shards).
Rebalancing data when scaling out.
4. Storage Growth:
At 3TB/month (36TB/year), SQL databases require significant storage scaling. Traditional SQL databases on single-node systems have limits on how much storage they can handle efficiently.
5. Cost and Maintenance:
Running large SQL clusters with replication, sharding, and backups can become expensive and operationally complex compared to distributed NoSQL databases designed for such scales.
But still we prefer to use Payment DB as database for acid transactions
HLD