
Design YouTube
A YouTube-like system is a video-sharing platform that supports various user interactions.

FR
1.Users can upload videos in various formats.
2.Generate video thumbnails.
3.Allow users to search videos by title, tags, or keywords.
4.Enable users to comment on videos.
5.Allow users to like or dislike videos.
6.Provide detailed analytics for content creators such as View count, watch time, audience retention and demographics of viewers.
7.Notify users about new uploads from subscribed channels.
8.User should be able to live stream videos
NFR
1.System should be highly scalable to handle millions of concurrent users and billions of video streams globally.
2.The search feature should return results in under 500ms.
3.Ensure 99.99% uptime for video streaming and essential services, thereby making system highly available
4.Support thousands of video uploads and millions of video views per minute.
Estimates
User Base
Active users per day: 1 billion (approx. 1/7th of the world population)
Concurrent users: 5% of daily active users ≈ 50 millionVideos viewed per user per day: 20
Total daily views: 20 billion
Views QPS=20B/10^5=20*10^4=200k QPS
Upload QPS=1M videos / day
QPS=1M/10^5=10QPSUploads per minute: 500 hours of video
Video length: Average 10 minutes
Video size: 5 MB/min at 720p resolution (base format)
500hours/min×60min/hour×5MB/min=150,000GB/day
1,050,000GB/day×365×5=1,917,500,000GB=1.92EB (Exabytes)API’s
1.Upload Video
Endpoint:
POST /videos/uploadDescription: Allows users to upload videos.
request { "userId": "12345", "title": "My Video", "description": "This is a test video", "tags": ["test", "demo"], "visibility": "public/private/unlisted" } reponse { "videoId": "abcd1234", "status": "uploading" }2.Check Upload Status
Endpoint:
GET /videos/{videoId}/statusDescription: Checks the status of a video upload.
{ "videoId": "abcd1234", "status": "processing/completed/failed" }
3.Update Video Details
Endpoint:
PUT /videos/{videoId}Description: Update metadata of a video.
{ "title": "Updated Title", "description": "Updated description", "tags": ["updated", "tags"] }
4.Fetch Video
Endpoint:
GET /videos/{videoId}Description: Retrieves video playback details.
{ "videoId": "abcd1234", "title": "My Video", "description": "Test description", "url": "https://cdn.example.com/abcd1234.mp4", "views": 1000, "likes": 500 }5.Stream Video
Endpoint:
GET /videos/{videoId}/streamDescription: Fetches a streaming URL for adaptive bitrate playback.
{ "streamUrl": "https://cdn.example.com/hls/abcd1234/master.m3u8" }
6.Search Videos
Endpoint:
GET /searchDescription: Search for videos based on keywords, tags, or other criteria.
Query Params:
query(string): Search term.tags(array): Tags for filtering.sort(string):relevance/recent.[ { "videoId": "abcd1234", "title": "My Video", "thumbnail": "https://cdn.example.com/thumbs/abcd1234.jpg" } ]
7.Fetch Recommendations
Endpoint:
GET /recommendations/{userId}Description: Fetch personalized video recommendations.
[ { "videoId": "xyz987", "title": "Recommended Video", "thumbnail": "https://cdn.example.com/thumbs/xyz987.jpg" } ]
8.Like/Dislike Video
Endpoint:
POST /videos/{videoId}/likeDescription: Like or dislike a video.
{ "userId": "12345", "action": "like/dislike" }
9.Comment on Video
Endpoint:
POST /videos/{videoId}/commentsDescription: Add a comment to a video.
request { "userId": "12345", "comment": "Great video!" }
10.Fetch Comments
Endpoint:
GET /videos/{videoId}/commentsDescription: Fetch comments for a video.
[ { "commentId": "cmt123", "userId": "56789", "content": "Great video!", "timestamp": "2024-01-01T10:00:00Z" } ]11.Subscribe to Notifications
Endpoint:
POST /notifications/subscribeDescription: Subscribe to notifications for a channel or user.
request{ "userId": "12345", "channelId": "channel789" }
12.Get Notifications
Endpoint:
GET /notificationsDescription: Fetch notifications for a user.
[ { "notificationId": "notif123", "message": "New video uploaded by Channel XYZ", "timestamp": "2024-01-01T10:00:00Z" } ]
DATABASES
1. Metadata Storage
Database: Relational Database (e.g., PostgreSQL, MySQL)
Stores structured information about videos, users, and channels.
Optimized for transactional queries like search, sorting, and filtering.
Video Table
CREATE TABLE videos ( video_id VARCHAR(50) PRIMARY KEY, title TEXT NOT NULL, description TEXT, user_id VARCHAR(50), upload_time TIMESTAMP, visibility ENUM('public', 'private', 'unlisted'), tags JSONB, status ENUM('processing', 'completed', 'failed'), views BIGINT DEFAULT 0, likes BIGINT DEFAULT 0, duration INT, -- in seconds thumbnail_url TEXT );Users Table
CREATE TABLE users ( user_id VARCHAR(50) PRIMARY KEY, username TEXT NOT NULL, email TEXT UNIQUE NOT NULL, created_at TIMESTAMP DEFAULT NOW(), subscription_level ENUM('free', 'premium') );Channels Table
CREATE TABLE channels ( channel_id VARCHAR(50) PRIMARY KEY, user_id VARCHAR(50), name TEXT NOT NULL, description TEXT, created_at TIMESTAMP DEFAULT NOW(), FOREIGN KEY (user_id) REFERENCES users(user_id) );2. Video Content Storage
Database: Distributed Object Storage (e.g., Amazon S3, Google Cloud Storage)
Stores raw video files, thumbnails, and encoded video streams.
Schema:
Metadata links to the storage location of videos.
/videos/{video_id}/original.mp4 /videos/{video_id}/1080p.mp4 /videos/{video_id}/720p.mp4 /thumbnails/{video_id}/thumbnail.jpg
3. Search and Discovery
Database: Search Engine (e.g., Elasticsearch, Apache Solr)
Provides full-text search and relevance ranking for videos.
{ "video_id": "abcd1234", "title": "My Test Video", "description": "This is a demo video for testing.", "tags": ["demo", "test"], "views": 1000, "likes": 50, "upload_time": "2024-01-01T12:00:00Z" }5. User Activity Logs
Database: Time-Series Database (e.g., InfluxDB, Prometheus)
Tracks events like views, likes, and watch times.
Schema:
Events Table
CREATE TABLE user_events ( event_id BIGSERIAL PRIMARY KEY, user_id VARCHAR(50), video_id VARCHAR(50), event_type ENUM('view', 'like', 'dislike', 'comment'), timestamp TIMESTAMP DEFAULT NOW(), duration INT -- In seconds (for views) );6. Analytics and Metrics
Database: Columnar Database (e.g., Apache Pinot, Google BigQuery)
Handles aggregated metrics and analytics queries.
Video Anlaytics Table
CREATE TABLE video_analytics ( video_id VARCHAR(50), date DATE, views BIGINT, likes BIGINT, watch_time BIGINT, -- Total watch time in seconds PRIMARY KEY (video_id, date) );User Analytics Table
CREATE TABLE user_analytics ( user_id VARCHAR(50), date DATE, total_watch_time BIGINT, total_videos_watched BIGINT, PRIMARY KEY (user_id, date) );7. Notifications
Database: Key-Value Store (e.g., Redis, Memcached)
Stores real-time notifications for users.
Schema:
Key:
notification:{user_id}Value: List of notification messages.
{ "notifications": [ { "message": "New video uploaded by Channel XYZ", "timestamp": "2024-01-01T12:00:00Z" }, { "message": "Your video has reached 1,000 views!", "timestamp": "2024-01-02T14:00:00Z" } ] }
8. Caching
Database: In-Memory Cache (e.g., Redis, Memcached)
Caches frequently accessed data like video metadata and recommendations.
Schema:
Key:
video:{video_id}Value: Serialized video metadata.
TTL: Set for invalidation after a specific duration.
This multi-database architecture ensures scalability, optimized performance for various use cases, and smooth integration across the platformOpen Ended Questions
Will the client directly talk to CDN to fetch the video or some service will talk to it?
1. Client-Server Interaction in Streaming
A. Initial Interaction with Backend Services
The client communicates with the backend (streaming or video service) for:
Fetching the video metadata (title, description, duration, etc.).
Obtaining the manifest file URL (e.g.,
master.m3u8ormanifest.mpd).
The backend provides a URL pointing to the manifest file on the CDN or object storage.
B. Direct Interaction with CDN
After receiving the manifest URL, the client directly fetches:
The manifest file from the CDN.
The video chunks specified in the manifest file, also served by the CDN.
The streaming service itself is not involved in the actual delivery of video chunks.
2. Why Clients Talk Directly to the CDN
A. Scalability
CDNs are designed for massive scale, with distributed edge servers that can handle billions of requests efficiently.
Offloading video delivery to a CDN reduces the load on backend servers, allowing them to focus on metadata and control logic.
B. Reduced Latency
CDNs cache content closer to end users, minimizing latency compared to fetching chunks from a central server or origin storage.
C. Cost Efficiency
Serving data from a CDN is typically more cost-effective than using backend services or raw object storage for direct content delivery.
D. Optimized for Streaming
CDNs support adaptive bitrate streaming, ensuring seamless playback by dynamically adjusting the video quality based on the user's bandwidth.
Does the Streaming Service Ever Proxy CDN?
In rare cases, the streaming service might act as an intermediary between the client and CDN:
A. When Proxying Makes Sense
Security or Authentication:
If stricter access control is required, the streaming service can authenticate the client and generate short-lived signed URLs for CDN access.
Customized Responses:
Dynamic generation of manifests based on user-specific preferences (e.g., language, subtitles).
Logging or Analytics:
To gather detailed insights about playback behavior or errors.
B. Downsides of Proxying
Adds latency and increases backend load.
Reduces the benefits of CDN scalability.
What Database YouTube uses for video metadata
What is Vitess?
Vitess is an open-source, distributed database solution that provides horizontal scaling for MySQL databases. It was originally developed by YouTube to manage its massive scale of data while keeping MySQL as the underlying relational database.
Vitess essentially acts as a MySQL cluster that is highly scalable, sharded, and capable of handling large amounts of traffic and data. It abstracts the complexity of managing a distributed MySQL setup and provides a single entry point to interact with the database.
Why Vitess for YouTube?
YouTube, being a massive platform, generates a huge amount of user and video-related metadata (e.g., user profiles, video views, likes, comments). Storing and querying this data efficiently, especially at scale, requires robust database technology. Here's why Vitess was used:
Horizontal Scalability: Vitess allows YouTube to split and distribute data across multiple MySQL instances, ensuring that it can scale horizontally to handle increasing traffic and data without compromising performance.
Sharding: Vitess uses sharding to distribute data across multiple databases based on predefined key values. This makes it possible to store and manage data in smaller chunks across different machines, making it more manageable and efficient.
High Availability and Reliability: Vitess provides built-in mechanisms for replication, failover, and backup, ensuring that YouTube's user metadata is always available, even during system failures.
SQL Compatibility: Vitess works with MySQL syntax and tooling, meaning YouTube can continue to use its existing MySQL tools and queries without having to migrate to a completely new database system.
Distributed Querying: It optimizes complex queries and allows users to run distributed queries across multiple shards seamlessly.
Vitess Use at YouTube
Vitess has been integral in scaling YouTube's infrastructure to handle millions of user interactions and metadata, such as:
User profiles, subscriptions, and activity history.
Video metadata, such as views, likes, comments, etc.
Channel and playlist management.
Real-time operations like querying and updating video metadata or user stats.
Vitess is used by YouTube to manage user metadata efficiently at massive scale. Its ability to scale MySQL horizontally through sharding and replication makes it an ideal choice for handling YouTube's vast, growing data, ensuring high availability and consistent performance.
How Pre-signed URLs Work for Video Uploads:
Backend Generates Pre-signed URL:
The server (backend) generates a pre-signed URL using cloud storage APIs (e.g., AWS S3 SDK).
This URL is signed with specific permissions (such as PUT access for uploading) and an expiration time, which restricts access.
The URL can also include other parameters, such as content-type restrictions or metadata that will be associated with the uploaded file.
Client Uploads Video:
The client (browser or mobile app) uses this pre-signed URL to upload the video directly to the cloud storage (e.g., S3) without going through your backend.
The upload is done via HTTP methods (typically
PUTfor direct file uploads) to the pre-signed URL.
Security:
Pre-signed URLs help ensure secure, temporary access to the storage service.
The server generates the URL with limited permissions, ensuring that the client can only upload to a specific bucket or path, and only within a defined time window.
Post-upload Processing:
Once the video is uploaded, the cloud storage service will trigger an event (like a notification or webhook), allowing the backend to perform any necessary post-processing, such as:
Transcoding the video.
Storing metadata (like duration, resolution, etc.) in a database.
Generating thumbnails or other assets.
Advantages of Using Pre-signed URLs for Video Uploads:
Reduced Server Load: The backend doesn’t need to handle large file uploads, reducing server load and network usage.
Scalability: Offloading file uploads to a cloud provider (like S3 or GCS) helps scale the upload process as your user base grows.
Security: Pre-signed URLs are time-limited, meaning they’re valid only for a short duration, reducing the risk of unauthorized access.
Direct Uploads: The client can upload directly to cloud storage, making the process faster and more efficient.
What is a Manifest File and how it useful in YouTube design?
A manifest file is a text-based file (usually in JSON or XML format) that provides metadata about the video content and its available formats. It acts as an index for the video player, listing:
Available video qualities (bitrate, resolution).
Audio tracks (languages, bitrate).
Subtitle tracks (languages).
Segment locations for streaming (URLs of video chunks).
For example, in the DASH protocol, the manifest file is called a Media Presentation Description (MPD), and for HLS, it's a playlist (.m3u8).
Purpose of Manifest Files in YouTube
1. Enabling Adaptive Bitrate Streaming (ABR)
What is ABR? Adaptive Bitrate Streaming allows YouTube to dynamically adjust the video quality based on the user's network conditions, device capabilities, and screen size.
The manifest file contains the URLs for video chunks at different bitrates and resolutions (e.g., 144p, 360p, 720p, 1080p, 4K). The player reads this file and switches between these versions during playback.
2. Video Chunking and Streaming
Instead of downloading the entire video file, YouTube divides videos into smaller chunks (e.g., 2-10 seconds per chunk).
The manifest file provides the location of these chunks, enabling the player to request only the segments it needs, reducing latency and buffering.
3. Efficient Bandwidth Usage
Users with slower networks can watch videos at lower resolutions. The manifest file allows the video player to choose the appropriate quality, ensuring smooth playback without buffering.
It prevents wasting bandwidth by fetching only the needed video and audio segments.
4. Support for Multiple Audio and Subtitle Tracks
If a video has multiple audio tracks (e.g., in different languages) or subtitles, the manifest file lists these options so the player can display them to the user.
5. Resilience to Failures
The manifest file contains multiple URLs for the same video chunk hosted on different CDNs or servers. This allows the player to switch servers if one becomes unavailable, ensuring uninterrupted playback.
6. Synchronization of Audio and Video Tracks
For videos with separate audio and video streams (common in adaptive streaming), the manifest file ensures that these tracks are synchronized during playback.
7. Enabling Advanced Features
Features like live streaming, DVR capabilities, and seeking within a video are supported by manifest files that contain information about the live stream or segment durations.
How Manifest Files Work in YouTube's Workflow
Video Transcoding and Chunking:
After a video is uploaded, YouTube transcodes it into multiple resolutions and formats (e.g., 144p to 4K).
The video is divided into small chunks for adaptive streaming.
Manifest File Creation:
A manifest file is generated for the video, listing the available bitrates, resolutions, audio tracks, and chunk URLs.
Storage in CDN:
The manifest file, along with the video and audio chunks, is stored on CDNs for efficient delivery to users worldwide.
Player Fetches the Manifest:
When a user plays a video, the YouTube player fetches the manifest file from the CDN and begins requesting video/audio chunks based on the user’s network and device capabilities.
Dynamic Adaptation:
As the network conditions change (e.g., a drop in speed), the player refers to the manifest file to switch to a lower-quality video stream.
Benefits of Using Manifest Files in YouTube
Scalability: Efficiently handles billions of daily views with varying network conditions.
Seamless Playback: Ensures smooth video delivery with adaptive streaming.
Bandwidth Optimization: Saves bandwidth by delivering only necessary video/audio segments.
Flexibility: Supports a wide variety of devices, resolutions, and network conditions.
How FCM/APN works in sending push notifications to the client device?
FCM is Google's cloud service for sending notifications to Android devices (and other platforms). Here's how it works:
1. Device Registers with FCM
The device (e.g., Android phone) registers with FCM and receives a registration token.
This registration token is a unique identifier for the device, similar to APN's device token, and is used to route messages to the correct device.
2. Backend Server Stores Registration Token
Your backend receives the registration token from the device and stores it. This token is essential for targeting the correct device for push notifications.
3. Backend Sends Notification Request to FCM
When you want to send a notification, your backend server constructs a push notification payload. The payload can include:
Title (e.g., "New Message").
Body (e.g., "You have a new message from John!").
Data (optional, to include custom key-value pairs, such as links, actions, etc.).
Notification options (e.g., priority, sound, icon).
Your backend sends the notification to FCM's HTTP endpoint. The server must authenticate using an API key or OAuth token.
POST https://fcm.googleapis.com/fcm/send Content-Type: application/json Authorization: key=YOUR_SERVER_KEY { "to": "device_registration_token", "notification": { "title": "New Message", "body": "You have a new message from John!" }, "data": { "custom_key": "custom_value" } }4. FCM Delivers the Notification
FCM receives the notification request from your backend and attempts to deliver the notification to the target device using the registration token.
If the device is unreachable or the app is not in the foreground, FCM will store the message and retry delivery.
5. Device Receives and Displays Notification
The device receives the push notification. If the app is in the foreground, the notification may be handled programmatically (e.g., showing an in-app banner). If it’s in the background, the system handles the display based on the notification's content.
Notification Flow Summary:
Device Registration: Device registers with the respective service (APN or FCM) and gets a unique token.
Backend: The backend stores the device token and constructs a notification payload.
Push Notification: The backend sends the payload to APN (for iOS) or FCM (for Android) along with the device token.
Service Delivery: APN or FCM delivers the notification to the device.
Device: The device processes and displays the notification, either in the background or foreground.
What Database to be used for likes/dislikes DB ?
Choosing the right database for a likes/dislikes database depends on factors like the scale of the application, the expected read/write patterns, and the need for consistency and latency.
For a platform like YouTube, which has billions of users and high engagement, the database must handle:
High Write Throughput: As millions of users continuously like/dislike videos.
Low-Latency Reads: For quickly displaying likes/dislikes count.
Efficient Aggregation: To calculate and display metrics like the total number of likes/dislikes.
Scalability: To accommodate billions of records for videos and user interactions
1. NoSQL Databases
NoSQL databases are generally well-suited for high-throughput, low-latency operations.
a. Cassandra
Why?
Distributed, highly scalable, and fault-tolerant.
Optimized for write-heavy workloads.
Allows for efficient querying of likes/dislikes counts and individual user interactions.
Horizontal scaling is easy.
Data Model:
Partition Key: Video ID.
Clustering Key: User ID (to track individual user actions).
Columns: Action (like/dislike), timestamp
CREATE TABLE likes_dislikes ( video_id UUID, user_id UUID, action TEXT, -- 'like' or 'dislike' timestamp TIMESTAMP, PRIMARY KEY (video_id, user_id) );
b. DynamoDB
Why?
Managed NoSQL database with built-in scalability.
Strong performance for high-volume read/write operations.
Supports TTL (Time to Live) for data retention policies if needed.
Data Model:
Partition Key: Video ID.
Sort Key: User ID.
Additional Attributes: Action, timestamp.
c. Redis (or Redis Streams)
Why?
In-memory database for ultra-low-latency reads/writes.
Suitable for maintaining real-time counts of likes/dislikes.
Can be used as a cache for frequently accessed data.
Use Case:
Store real-time counters of likes/dislikes per video.
Use a backend store (like Cassandra or DynamoDB) for persistent storage.
HSET video_likes:video_id likes_count 123 dislikes_count 45
One can use Kafka and Flink to create a robust, real-time pipeline for processing likes/dislikes data in a scalable and fault-tolerant way.
Here’s how and why this setup works:
Why Use Kafka and Flink?
Decoupling Components:
Kafka acts as a durable message broker that decouples the system components.
Even if Flink or another consumer is temporarily unavailable, Kafka ensures no data is lost.
Real-Time Aggregation:
Flink can process streams of likes/dislikes data in real time and maintain aggregated counters (e.g., total likes/dislikes per video).
It supports stateful processing with exactly-once guarantees.
Scalability:
Kafka handles millions of events per second.
Flink scales horizontally to process high-throughput streams.
Durability and Replay:
Kafka retains the event logs, allowing you to replay data streams if needed (e.g., to recompute aggregates or debug issues).
Workflow: Putting Likes in Redis, Kafka, and Aggregating with Flink
1. User Action
A user clicks "like" or "dislike" for a video.
This action is recorded in Redis for immediate real-time read/write operations.
2. Push to Kafka
After writing to Redis, the like/dislike action (along with metadata such as user ID, video ID, timestamp, and action) is pushed to a Kafka topic.
Kafka Schema example
{ "user_id": "12345", "video_id": "abcd1234", "action": "like", "timestamp": 1699999999999 }3. Flink for Real-Time Aggregation
Stream Processing:
Flink reads the data from Kafka.
Aggregates likes/dislikes per video in real time using tumbling or sliding windows.
Stateful Aggregation:
Flink maintains state (e.g., running totals of likes/dislikes) in its internal state store or an external state backend (e.g., RocksDB).
Output Aggregation:
Results are stored in a persistent database (e.g., Cassandra, DynamoDB) for long-term storage or used to update the Redis counters for faster reads.
4. Write Aggregates Back to Redis
The aggregated counts from Flink are periodically updated in Redis for real-time display on the frontend.
Detailed Data Flow
Frontend to Redis:
Write: User actions (like/dislike) are immediately written to Redis for caching.
Read: The frontend fetches counts from Redis to display likes/dislikes.
Redis to Kafka:
The user action is asynchronously pushed to Kafka after being stored in Redis.
Kafka topics may include:
likes-dislikes-raw: Raw user actions.likes-dislikes-aggregates: Aggregated data from Flink.
Kafka to Flink:
Flink consumes messages from
likes-dislikes-raw:Groups by video ID.
Maintains a running total of likes/dislikes.
Outputs aggregated data to
likes-dislikes-aggregates.
Flink to Persistent Store:
Flink updates:
Redis: For real-time counters.
Long-Term DB: For persistent storage (e.g., Cassandra, DynamoDB).
Advantages of This Pipeline
Real-Time Feedback: Redis ensures the system responds instantly to user actions.
Scalability: Kafka and Flink can handle high throughput, ensuring scalability for billions of users.
Fault Tolerance: Kafka ensures durability, and Flink provides exactly-once guarantees for data consistency.
Flexibility: Aggregation logic in Flink can be modified to add new metrics without affecting the rest of the system.
When Not to Use Flink or Kafka
If the system is small (e.g., fewer than 10 million users) or the real-time aggregation requirements are less demanding:
Skip Kafka and Flink.
Use Redis alone for counters and perform periodic batch updates to a persistent database.
HLD
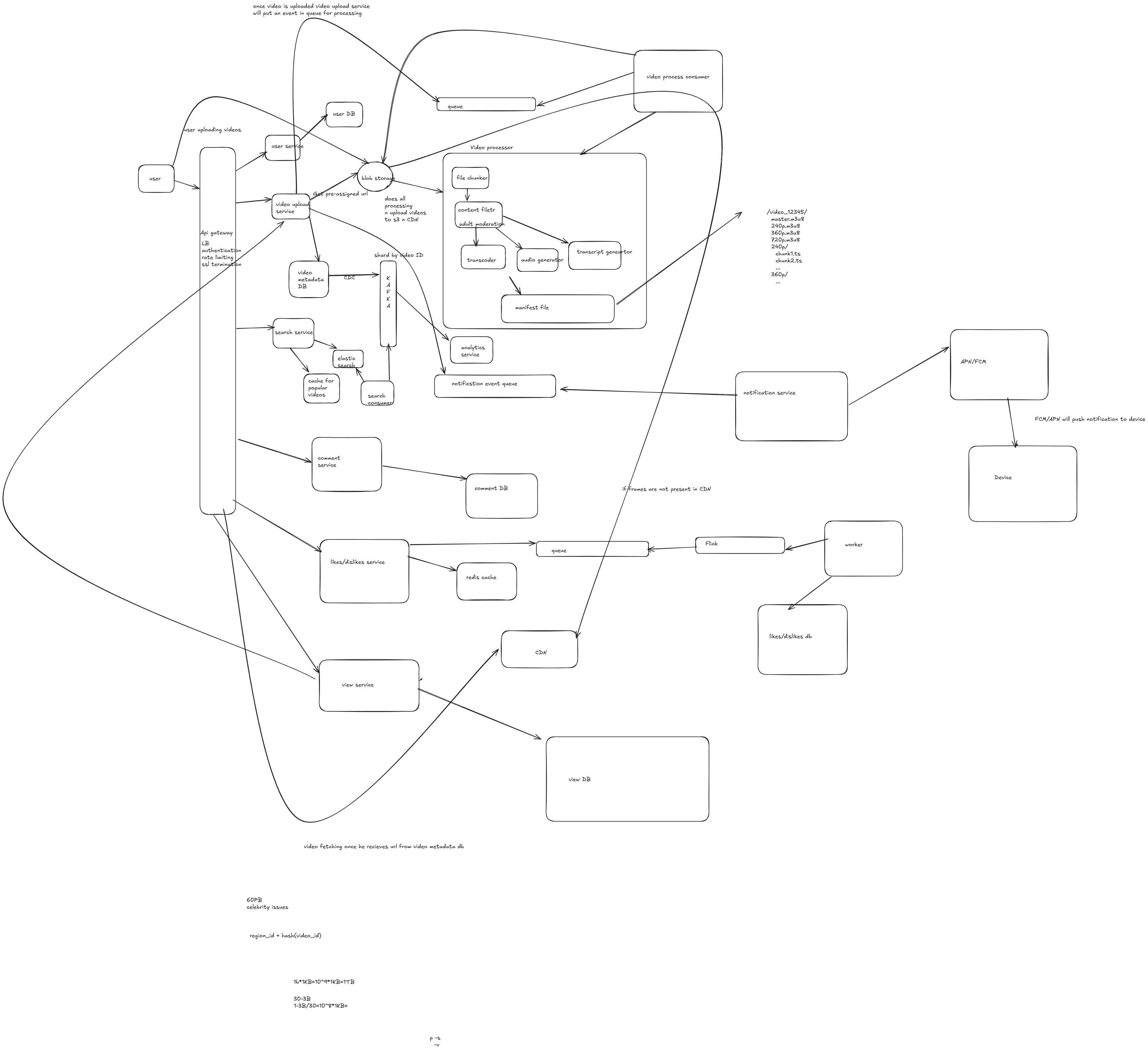
what is the shard Key that is used for video metadata?
Using region_id + video_id as a sharding strategy for video metadata in a system like YouTube has both pros and cons. Let’s evaluate whether it is a good strategy based on the use case and query patterns.
Advantages
Data Locality for Regional Queries:
Region-specific queries (e.g., fetching videos popular in a specific region) would benefit as the metadata for all videos from a particular region will reside on the same shard.
This reduces cross-shard lookups for region-specific queries.
Improved Distribution:
Adding
video_idensures better distribution of data within each region, asvideo_idacts as a secondary unique identifier. This prevents hotspots in shards dominated by a particular region.
Scalability:
The combination provides a scalable partitioning key by balancing data across shards geographically (via
region_id) and by the volume of videos (viavideo_id).
Efficient Updates:
Video updates are localized to a single shard, improving the performance of update operations as no cross-shard communication is needed.
Disadvantages
Category-Based or Global Queries:
Queries that span multiple regions, such as global searches or trending videos worldwide, will require querying multiple shards. This could increase latency for such use cases.
Uneven Load Distribution:
Certain regions might have significantly higher traffic than others (e.g., North America vs. a smaller region), leading to uneven load distribution across shards.
If
region_iddominates the sharding key, high-traffic regions could overload certain shards, even with thevideo_idcomponent.
Complex Query Logic:
Combining
region_idandvideo_idrequires application logic to be aware of this composite key when querying or inserting data. This increases complexity.
Multi-Region Users:
Videos that are popular in multiple regions may lead to redundant queries or the need to replicate metadata across shards, complicating synchronization.
When is region_id + video_id a Good Strategy?
This strategy works well in these scenarios:
Region-Specific Features:
The majority of queries involve fetching videos based on regional preferences or regulations.
Example: Serving region-specific trending videos, or complying with region-based content restrictions.
Balanced Regional Traffic:
Regions have relatively balanced traffic or sharding logic includes additional load-balancing mechanisms.
Write-Heavy Systems:
If the system is write-heavy and updates are more frequent than global reads, this strategy avoids cross-shard writes and ensures good write throughput.
When to Avoid region_id + video_id?
Global or Category-Centric Queries Dominate:
Systems where queries often fetch videos across regions or categories (e.g., trending videos across categories worldwide).
In such cases, consider sharding by category + video_id or just video_id for more even distribution.
Imbalanced Regional Load:
When certain regions generate significantly higher traffic, consider other load-distributing strategies (e.g., hash(video_id)) to avoid regional hotspots.
Alternatives
Hash(video_id):
Ensures even data distribution and avoids regional hotspots. However, it sacrifices data locality for region-specific queries.
Category + video_id:
Useful if most queries are category-based (e.g., "all sports videos"). However, it may not handle regional queries efficiently.
Hybrid Strategy (Region-Specific and Global Clusters):
Maintain separate clusters for region-specific queries and global queries.
Use
region_id + video_idin regional clusters andhash(video_id)for global clusters.
Conclusion
Using region_id + video_id as a sharding key is good for systems with a strong focus on regional queries and balanced regional traffic. However, for systems with heavy global query demands or imbalanced regional loads, you may need to consider hybrid or alternative strategies to balance locality and scalability. Always base the decision on query patterns and traffic distribution.
4o