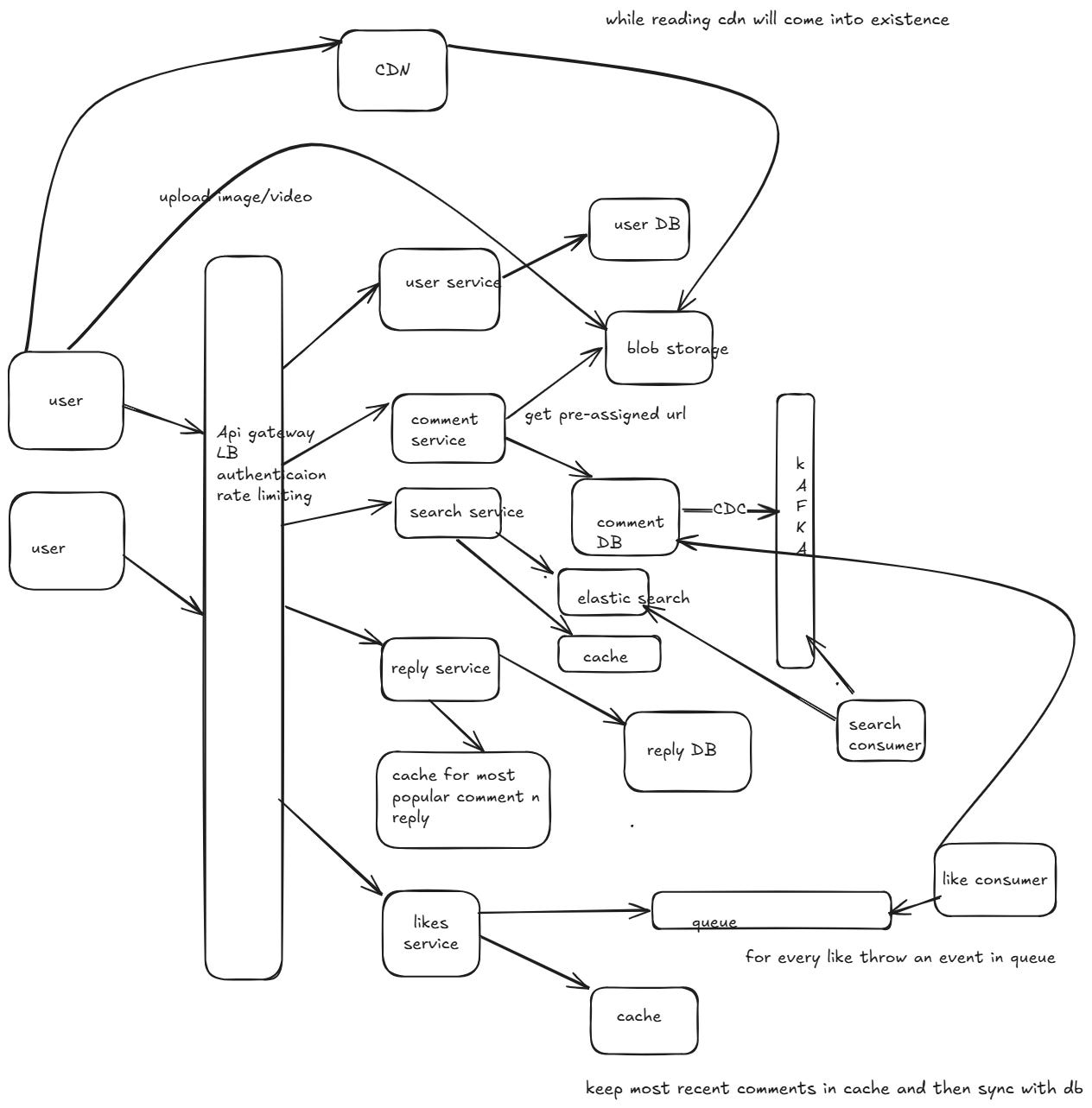
Designing a comment system for a large website

FR
1.Users can add comments on posts, articles, or other entities.
2.Display a list of comments for a given post or entity.
3.Support for nested replies (threaded conversations).(upto limit 4)
4.Allow users to edit or delete their own comments.
5.Sort comments by relevance, popularity, or newest/oldest.
6.Users can tag or mention other users in comments.
7.Allow users to attach images, videos, or links to their comments.
8.Users can react to comments (like, dislike, or other emoji-based reactions).
NFR
1.Display new comments or replies in real-time without refreshing the page,ensuring low latency
2.Searching comments must be done in real time
3.System should be highly available
4.System should be eventual consistent while diplaying comments.
5.System should be highly scalable to handle millions of comments across thousands of posts.
Estimates
Write QPS
Number of Users: 100 million users.
10% are active daily = 10 million daily active users (DAU).
Each active user posts 2 comments/day on average.
Total new comments per day = 20 million comments.
write QPS=20M/10^5=200qpsRead QPS
Comment Read Frequency:
On average, each comment is viewed 10 times.
Total read operations per day = 200 million reads.
Read QPS=200M/10^5=2k QPSComment Storage size
Comment text (256 characters): 200 bytes.
Metadata (user ID, post ID, timestamp, etc.): 200 bytes.
Total size per comment = 500 bytes
Total storage=20M*500bytes=10GB/day
For five years=10GB/day*400*5=20000GB=20TBAPI’s
1.POST api/v1/comments
Allow users to post a comment on a specific entity (e.g., blog post, video).
request
{
"entity_id": "12345", // ID of the entity being commented on
"user_id": "56789", // ID of the user posting the comment
"comment_text": "This is a great post!",
"parent_comment_id": "98765" // Optional for replies
}
response
{
"status": "success",
"comment_id": "112233",
"timestamp": "2024-11-21T10:00:00Z"
}
2.GET api/v1/comments?entity_id=12345&page=1&page_size=20&sort=recent
Retrieve all comments for a specific entity.
{
"entity_id": "12345",
"comments": [
{
"comment_id": "112233",
"user_id": "56789",
"comment_text": "This is a great post!",
"timestamp": "2024-11-21T10:00:00Z",
"likes": 15,
"replies": 5
},
{
"comment_id": "112234",
"user_id": "56790",
"comment_text": "I completely agree!",
"timestamp": "2024-11-21T10:05:00Z",
"likes": 8,
"replies": 0
}
],
"page": 1,
"page_size": 20,
"total_comments": 150
}
3.POST api/v1/comments/reply
Post a reply to an existing comment.
request
{
"parent_comment_id": "112233",
"user_id": "56789",
"comment_text": "I agree with you!"
}
reponse
{
"status": "success",
"reply_id": "445566",
"timestamp": "2024-11-21T10:15:00Z"
}
4.PUT api/v1/comments/{comment_id}
Allow users to edit their own comments.
request
{
"comment_text": "This is an updated comment."
}
reponse
{
"status": "success",
"updated_timestamp": "2024-11-21T10:30:00Z"
}
5.DELETE api/v1/comments/{comment_id}
Allow users or moderators to delete a comment.
{
"status": "success",
"deleted_comment_id": "112233"
}
6.POST api/v1/comments/{comment_id}/reactions
Allow users to react to a comment.
request
{
"user_id": "56789",
"reaction": "like" // Or "dislike"
}
reponse
{
"status": "success",
"likes": 16,
"dislikes": 3
}
7.GET api/v1/comments/{comment_id}/replies?page=1&page_size=10
Retrieve replies for a specific comment.
{
"comment_id": "112233",
"replies": [
{
"reply_id": "445566",
"user_id": "56790",
"comment_text": "I agree with you!",
"timestamp": "2024-11-21T10:15:00Z"
}
],
"page": 1,
"page_size": 10,
"total_replies": 50
}
8.GET api/v1/comments/search?entity_id=12345&query=great&page=1&page_size=20
Search for comments containing specific keywords
{
"query": "great",
"results": [
{
"comment_id": "112233",
"user_id": "56789",
"comment_text": "This is a great post!",
"timestamp": "2024-11-21T10:00:00Z"
}
],
"page": 1,
"page_size": 20,
"total_results": 5
}
9.POST api/v1/comments/{comment_id}/flag
Allow users to flag a comment for moderation.
request
{
"user_id": "56789",
"reason": "Spam"
}
response
{
"user_id": "56789",
"reason": "Spam"
}
Databases
A comment system for a large-scale website involves multiple kinds of databases, each optimized for specific use cases. Below are the types of databases you could use, their roles, and proposed schemas.
1. Relational Database (RDBMS)
Use Case: Ensure strong consistency, relational integrity, and efficient querying for structured data like comments and their relationships.
Example: MySQL/PostgreSQL
Schema Design:
CREATE TABLE Comments ( comment_id SERIAL PRIMARY KEY, entity_id VARCHAR(255) NOT NULL, -- ID of the post or article user_id VARCHAR(255) NOT NULL, -- ID of the user who posted the comment comment_text TEXT NOT NULL, parent_comment_id INT REFERENCES Comments(comment_id), -- For replies created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP, likes INT DEFAULT 0, dislikes INT DEFAULT 0 ); CREATE INDEX idx_entity_id ON Comments(entity_id); -- For faster queries by entity
2.2. NoSQL Document Database
Use Case: Store comments as hierarchical documents, ideal for fast reads and writes.
Example: MongoDB
Schema Design (Nested Documents):
{ "entity_id": "12345", "comments": [ { "comment_id": "112233", "user_id": "56789", "comment_text": "This is a great post!", "likes": 15, "dislikes": 2, "created_at": "2024-11-21T10:00:00Z", "replies": [ { "reply_id": "445566", "user_id": "56790", "comment_text": "I agree with you!", "likes": 5, "dislikes": 0, "created_at": "2024-11-21T10:15:00Z" } ] } ] }Flexible Schema
3. Key-Value Store
Use Case: Cache frequently accessed data like recently posted or most liked comments.
Example: Redis/Memcached
Schema Design:
Key:
entity_idValue: JSON array of comments (e.g., top 100 most liked comments for an entity)
Key: "comments:entity:12345" Value: [ { "comment_id": "112233", "user_id": "56789", "comment_text": "This is a great post!", "likes": 15, "created_at": "2024-11-21T10:00:00Z" }, ... ]
4. Wide-Column Store
Use Case: Handle large-scale comment data with high write throughput and efficient range queries.
Example: Apache Cassandra
CREATE TABLE Comments (
entity_id TEXT,
comment_id UUID,
user_id TEXT,
comment_text TEXT,
parent_comment_id UUID,
likes INT,
dislikes INT,
created_at TIMESTAMP,
PRIMARY KEY (entity_id, created_at)
);
5. Search Engine
Use Case: Enable full-text search for comments.
{
"mappings": {
"properties": {
"comment_id": { "type": "keyword" },
"entity_id": { "type": "keyword" },
"user_id": { "type": "keyword" },
"comment_text": { "type": "text", "analyzer": "standard" },
"created_at": { "type": "date" },
"likes": { "type": "integer" }
}
}
}
6. Graph Database
Use Case: Represent relationships between comments (e.g., reply chains, user interactions).
Example: Neo4j
Schema Design:
Nodes:
Comment,User,Entity.Relationships:
User -> [POSTED] -> CommentComment -> [REPLIED_TO] -> CommentComment -> [BELONGS_TO] -> EntityCREATE (:User {user_id: "56789"}) CREATE (:Comment {comment_id: "112233", text: "This is a great post!"}) CREATE (:Entity {entity_id: "12345"}) CREATE (u)-[:POSTED]->(c)-[:BELONGS_TO]->(e)
Combining Databases
For a highly scalable comment system, you might use polyglot persistence:
Relational Database: Store core comment data and ensure consistency.
Document Database: Serve hierarchical threads and optimize for flexible querying.
Key-Value Store: Cache frequently accessed comments for low-latency reads.
Wide-Column Store: Store massive-scale data for high-throughput operations.
Search Engine: Full-text search and advanced filtering.
Graph Database: Analyze relationships between users and comments.Reason behind using Dynamo DB for comments DB
1.Sharding by Partition Key: DynamoDB stores data by distributing it across multiple partitions based on the hash of the partition key.
2.Each partition is an independent storage unit and is designed to handle up to 10 GB of data and 3,000 RCU (read capacity units) or 1,000 WCU (write capacity units).
As your data grows, DynamoDB automatically adds more partitions.
3.Each item is a key-value pair, where the key is a combination of the partition key (and optionally a sort key), and the value is stored as a document-like structure (JSON-like).
4.Data is stored in small immutable SSTables (Sorted String Tables), similar to the structure used in LSM (Log-Structured Merge) Trees, making it suitable for heavy writes.Schema
Primary Key
Partition Key (PK): PostID (indicates the post the comment belongs to)
Sort Key (SK): CommentID (ensures uniqueness and allows ordering)
Attribute Data Type Description
PostID String ID of the post the comment belongs to
CommentID String Unique identifier for the comment (e.g., timestamp-based)
ParentID String ID of the parent comment (null for top-level comments)
UserID String ID of the user who posted the comment
Content String Text of the comment
Timestamp String Timestamp of when the comment was posted
Likes Number Number of likes for the comment
Indexes for Efficient Queries
Global Secondary Index (GSI)
To fetch recent comments for a post:
Index Name: PostID-Timestamp-Index
Partition Key: PostID
Sort Key: Timestamp
Query: Fetch PostID = 'Post123', sorted by Timestamp in descending order for recent comments.
To retrieve top K comments by likes for a post:
Index Name: PostID-Likes-Index
Partition Key: PostID
Sort Key: Likes (descending order)Other option could be Mongo DB or Cassandra?
Why Mongo is good choice?
Your application requires a flexible schema, such as storing nested structures for comments and replies.
You need rich querying capabilities (e.g., sorting, aggregations) to retrieve the top K recent comments and replies.
You are dealing with moderate to high read and write throughput but not massive scaling needs.Why Cassandra could be good choice?
Your application needs horizontal scalability and is expecting high write throughput.
You prioritize availability and can tolerate eventual consistency.
You don't require complex joins or aggregation operations but need fast access to comments and replies in a write-heavy environment.Conclusion:
For moderate to high read/write requirements with flexibility: MongoDB is likely the better choice.
For large-scale, high-write environments with fast access: Cassandra is a good fit.HLD