
Designing a scalable system for a smart city that processes data from millions of sensors, collects readings in real-time, and computes hourly averages efficiently.
Let's design the system

FR
1.Ingest data from millions of IoT sensors deployed across the city.
2.Support multiple data sources (e.g., weather stations, traffic monitors, pollution sensors).
3.Compute hourly averages for sensor readings.
4.Support real-time and batch processing for analytics.
5.Handle different types of sensor data (temperature, humidity, CO₂ levels, traffic flow, etc.).
6.Trigger alerts when thresholds are exceeded (e.g., air pollution, traffic congestion)
7.Provide dashboards to monitor real-time sensor data.
8.Ensure data encryption during transmission and storage.
NFR
1.System should be highly scalable to handle high-frequency sensor updates (e.g., every second or minute).
2.The system should scale horizontally to support millions of sensors and increasing data volumes.
3.Ensure real-time data ingestion with minimal delay (e.g., under 1 second for critical alerts).
4.The system should have 99.99% uptime with redundancy.
5.Ensure no data loss by using durable storage (e.g., distributed databases, message queues)
Estimates
Number of sensors=10M
Data collection rate= every 10 seconds = 6 reading per minute
each reading size=200 bytesWrite QPS= 10M*6*60*24/10^5=API’s
1.POST api/v1/sensor-data
request {
"sensor_id": "sensor-12345",
"location": { "latitude": 37.7749, "longitude": -122.4194 },
"timestamp": "2025-02-04T10:15:30Z",
"data": { "temperature": 25.6, "humidity": 55, "air_quality": 42 }
}
response { "message": "Data received successfully", "status": "success" }
2.GET /sensor-data?sensor_id={id}&start_time={}&end_time={} → Get raw sensor readings within a time range
{
"sensor_id": "sensor-12345",
"data": [
{ "timestamp": "2025-02-04T10:00:00Z", "temperature": 25.6 },
{ "timestamp": "2025-02-04T10:05:00Z", "temperature": 26.0 }
]
}
3.GET /aggregated-data?location={lat,lon}&metric={temperature}&interval=hourly
Fetch hourly averages for a given location and metric
{
"location": { "latitude": 37.7749, "longitude": -122.4194 },
"metric": "temperature",
"aggregated_data": [
{ "timestamp": "2025-02-04T10:00:00Z", "average": 25.4 },
{ "timestamp": "2025-02-04T11:00:00Z", "average": 26.1 }
]
}
POST api/v1/alerts
request { "sensor_id": "sensor-67890", "threshold": { "temperature": { "max": 40, "min": -10 } }, "notification_method": "email", "recipient": "admin@smartcity.com" } response { "message": "Alert configured successfully" }
5.GET /alerts?location={lat,lon} → Get active alerts for a specific location
6.POST api/v1/sensors/register → Register a new sensor
request {
"sensor_id": "sensor-98765",
"type": "air_quality",
"location": { "latitude": 37.7749, "longitude": -122.4194 }
}
response{ "message": "Sensor registered successfully" }
7.GET /sensors/{sensor_id} → Get sensor details
8.GET /dashboard/summary → Fetch city-wide sensor data summary
GET /dashboard/historical-trends?metric=traffic_flow&period=7d→ Get historical trends for analytics
Databases
Sensor Metadata Database (PostgreSQL / MongoDB)
Stores metadata for each registered sensor.
Table: sensors (PostgreSQL)
CREATE TABLE sensors (
sensor_id UUID PRIMARY KEY,
name VARCHAR(255),
type VARCHAR(100),
location GEOMETRY(Point, 4326), -- Stores latitude & longitude
owner_id UUID REFERENCES users(user_id),
status VARCHAR(20) CHECK (status IN ('active', 'inactive', 'faulty')),
created_at TIMESTAMP DEFAULT NOW()
);
Table: users (PostgreSQL)
CREATE TABLE users (
user_id UUID PRIMARY KEY,
username VARCHAR(100) UNIQUE NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
role VARCHAR(50) CHECK (role IN ('admin', 'operator', 'viewer')),
created_at TIMESTAMP DEFAULT NOW()
);
2️⃣ Time-Series Sensor Data (Cassandra / TimescaleDB)
Stores raw sensor readings with a high ingestion rate.
Table: sensor_data (Cassandra)
CREATE TABLE sensor_data (
sensor_id UUID,
timestamp TIMESTAMP,
metric_type TEXT,
value DOUBLE,
PRIMARY KEY ((sensor_id), timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC);
Why Cassandra?
Supports high write throughput.
Can scale horizontally across multiple nodes.
Aggregated Data Storage (TimescaleDB)
Stores hourly & daily averages to reduce query complexity.
Table: aggregated_sensor_data (TimescaleDB)
CREATE TABLE aggregated_sensor_data (
sensor_id UUID,
timestamp TIMESTAMP,
metric_type TEXT,
hourly_avg DOUBLE,
daily_avg DOUBLE,
PRIMARY KEY (sensor_id, timestamp)
);
Why TimescaleDB?
Provides efficient time-series storage & compression.
Allows easy querying for historical trends.
Alert & Notification Data (Redis / PostgreSQL)
Used for real-time monitoring & quick lookups.
alerts:{sensor_id} → {"threshold": 100, "condition": ">", "last_triggered": "2024-02-04T12:30:00Z"}
Why Redis?
Low latency for real-time threshold checks.
Table: alert_history (PostgreSQL)
CREATE TABLE alert_history (
alert_id UUID PRIMARY KEY,
sensor_id UUID REFERENCES sensors(sensor_id),
triggered_at TIMESTAMP DEFAULT NOW(),
metric_type TEXT,
value DOUBLE,
threshold DOUBLE,
condition TEXT
);
Analytical & Reporting Database (ClickHouse / Elasticsearch)
Stores historical data for dashboard queries & analytics.
Table: sensor_insights (ClickHouse)
CREATE TABLE sensor_insights (
sensor_id UUID,
timestamp TIMESTAMP,
metric_type TEXT,
avg_value DOUBLE,
max_value DOUBLE,
min_value DOUBLE
) ENGINE = MergeTree()
ORDER BY (sensor_id, timestamp);
Why ClickHouse?
Fast querying for large datasets.
Columnar storage optimizes analytical queries.
HLD
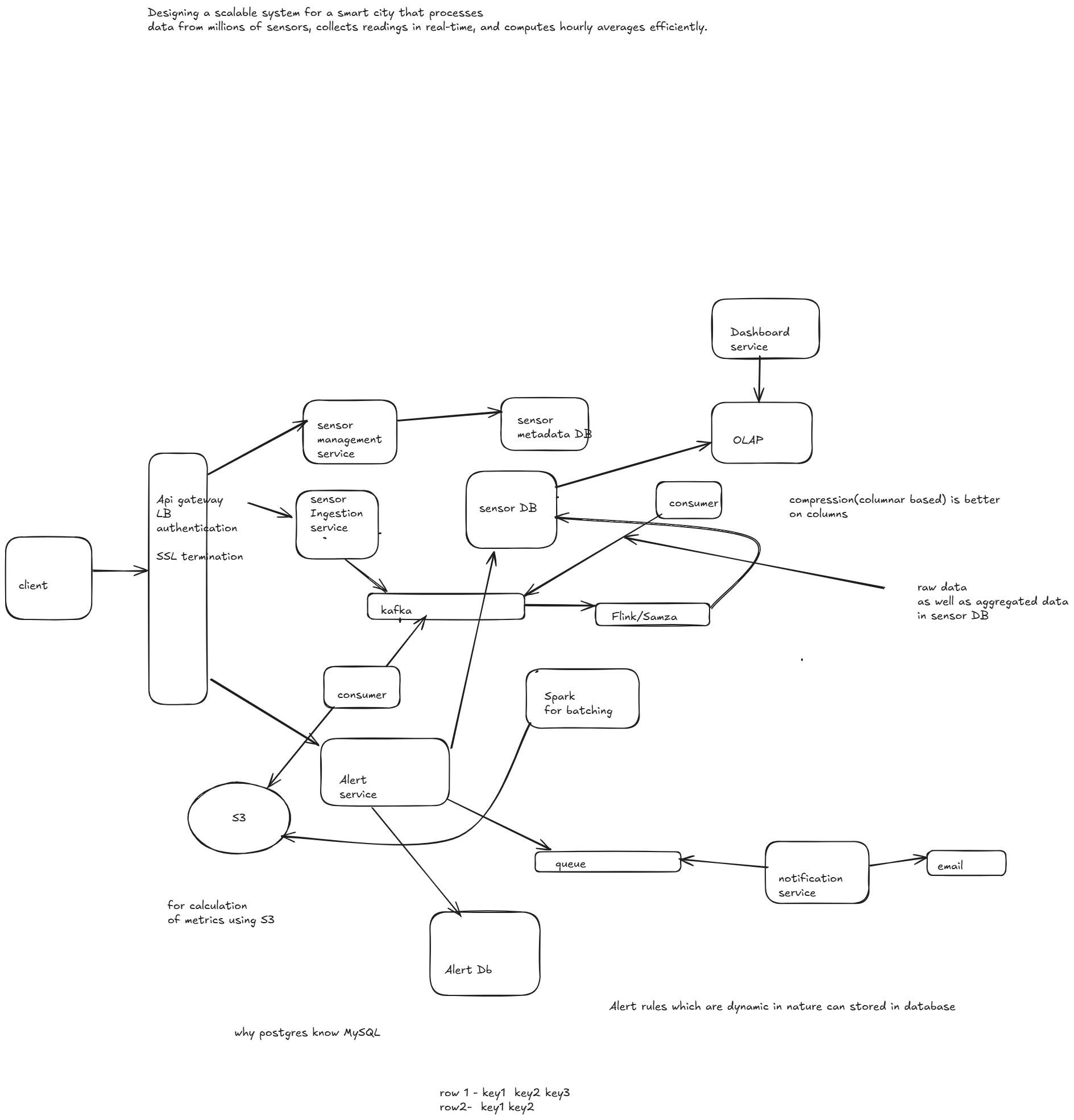
Why timeseries database is best suited for Sensor DB over cassandra?
Cassandra is a great NoSQL database for high-write, distributed workloads, but Time-Series Databases (TSDBs) like InfluxDB, TimescaleDB, or OpenTSDB are specifically optimized for time-series data, making them a better choice for storing IoT sensor data.

🔹 1. Optimized for Time-Series Queries
TSDBs auto-index timestamps, making queries like “last 1 hour of data” much faster.
Example Query (TimescaleDB):
SELECT time_bucket('5 minutes', timestamp) AS interval, avg(temperature)
FROM sensor_data
WHERE timestamp > now() - interval '1 day'
GROUP BY interval ORDER BY interval;
🚀 Cassandra struggles with this unless you manually design a partitioning strategy.
🔹 2. Efficient Storage & Compression
TSDBs use time-series compression algorithms (e.g., Gorilla, Delta encoding), reducing storage costs.
Cassandra stores each entry separately, making historical sensor data inefficient to store.
📌 Example: InfluxDB compresses sensor data up to 90% compared to Cassandra!
🔹 3. Native Support for Downsampling & Retention
TSDBs allow automated downsampling (e.g., store raw data for a week, then keep hourly averages).
In Cassandra, you must manually delete or aggregate old data.
📌 Example: Setting a retention policy in InfluxDB
CREATE RETENTION POLICY "one_month" ON "sensors" DURATION 30d REPLICATION 1 DEFAULT;
🚀 Automatically removes old data, saving storage!
🔹 4. Built-in Real-Time Aggregations & Alerts
TSDBs like TimescaleDB & InfluxDB support real-time streaming queries.
Cassandra requires external processing with Spark/Flink.
📌 Example: Continuous aggregation in InfluxDB
CREATE CONTINUOUS QUERY avg_temp_1h ON sensors
BEGIN
SELECT mean(temperature) INTO hourly_temp FROM sensor_data GROUP BY time(1h);
END
🚀 Automatically calculates hourly temperature averages!
🔹 5. High Write Performance with Time-Based Partitioning
TSDBs automatically partition data by time, making writes & queries efficient.
Cassandra requires manual partitioning strategies to avoid hotspots.
📌 Example: TimescaleDB partitions data into chunks by time
SELECT create_hypertable('sensor_data', 'timestamp', chunk_time_interval => INTERVAL '1 day');
🚀 Queries on recent data are super fast!
🔹 When to Use Cassandra for Sensor Data?
Use Cassandra only if: ✅ You need multi-region, distributed writes across data centers.
✅ You want a general-purpose NoSQL DB with wide-column storage.
✅ You have a team experienced in Cassandra partitioning & indexing.
🔹 TL;DR: Why TSDB is Best for Sensor Data?
✅ Optimized for time-series queries (auto-indexing on time).
✅ Efficient storage & compression (90% smaller than Cassandra).
✅ Built-in retention policies & downsampling (Cassandra requires manual deletion).
✅ Real-time aggregations & alerts (Cassandra needs external tools).
✅ Better query performance for time-based lookups.