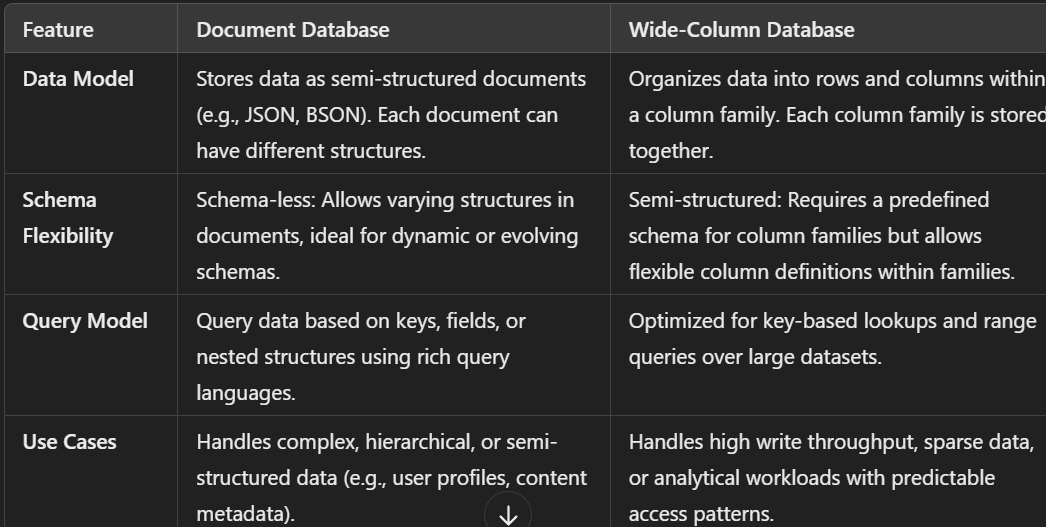
Difference between Document Databases and Wide column Databases and in which scenarios we need to use such databases?
Let's dissect each one of them

Document Databases: An In-Depth Overview
A document database is a type of NoSQL database that stores data in the form of documents—typically JSON, BSON, or XML. These databases are designed to handle semi-structured or unstructured data, offering flexibility and scalability for modern applications.
1. Core Concepts of Document Databases
Document as the Basic Unit:
A document is a self-contained unit of data that may include fields, key-value pairs, arrays, and nested objects.
{
"id": "123",
"name": "John Doe",
"email": "john.doe@example.com",
"addresses": [
{
"type": "home",
"city": "New York"
},
{
"type": "work",
"city": "San Francisco"
}
]
}
Schema Flexibility:
Unlike relational databases, document databases do not enforce a fixed schema.
Different documents in the same collection can have varying fields and structures.
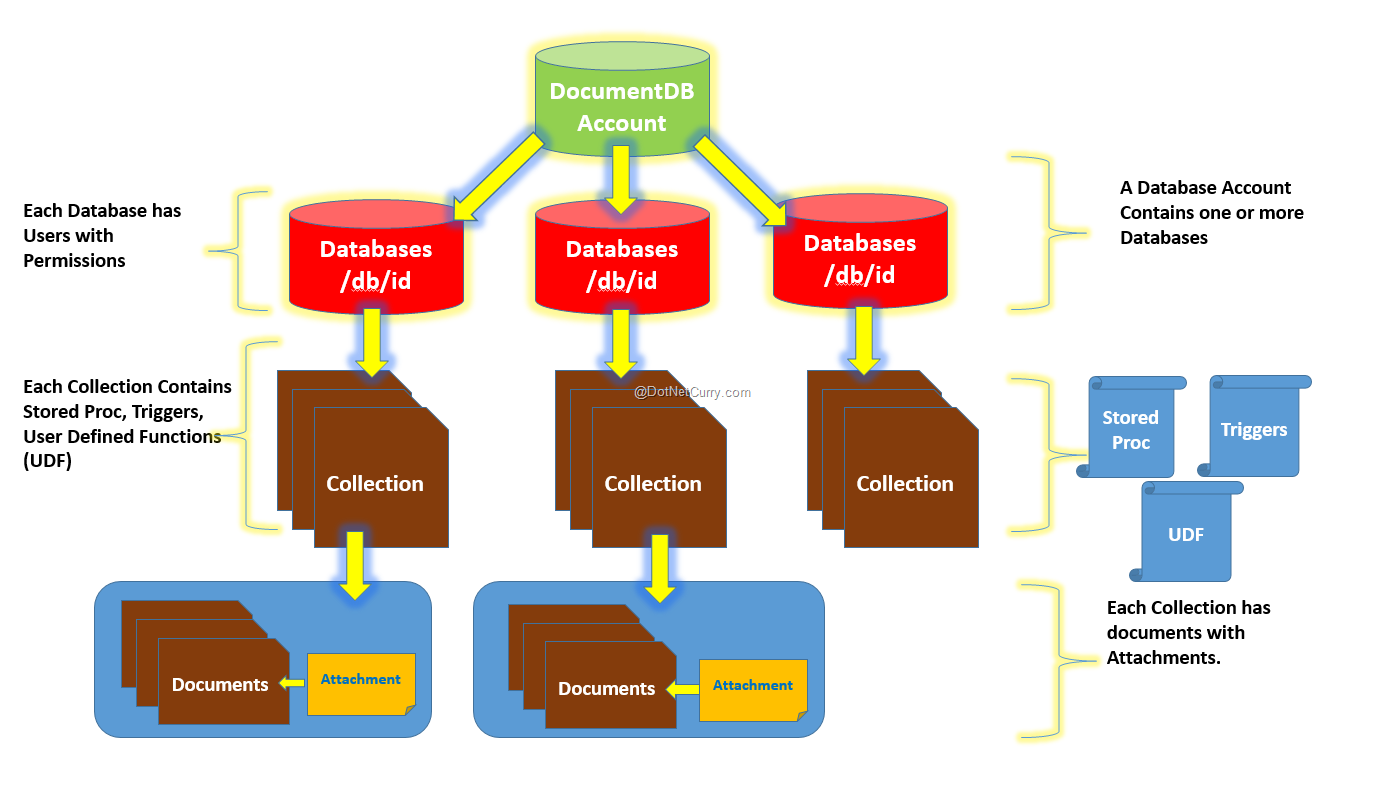
Collections:
Documents are grouped into collections, which are analogous to tables in relational databases but without rigid schemas.
Indexes:
Fields within documents can be indexed to optimize query performance.
Example: Indexing the
namefield in a collection for fast lookups.
Key-Based Access:
Each document typically has a unique identifier (e.g.,
_idin MongoDB), enabling fast key-based lookups.
2. Features of Document Databases
Hierarchical Data Representation:
Ideal for representing hierarchical or nested relationships within a single document.
Example: Storing a blog post and its comments in the same document.
Rich Query Language:
Supports queries based on nested fields, array elements, and full-text search.
{
"addresses.city": "New York"
}
Schema Evolution:
Fields can be added or removed from documents without requiring schema migrations.
Scalability:
Designed for horizontal scaling via sharding, distributing documents across multiple nodes.
Embedded Relationships:
Related data can be embedded within documents, reducing the need for complex joins.
3. Advantages of Document Databases
Flexibility:
Dynamic schema allows quick adaptation to evolving data requirements.
Performance:
Embedding related data reduces the need for joins, improving read performance for certain use cases.
Ease of Development:
Works seamlessly with JSON-based APIs, making it developer-friendly for modern web applications.
Horizontal Scalability:
Built-in support for sharding and replication ensures scalability across large datasets.
Real-Time Applications:
Supports fast writes and updates, making it ideal for real-time applications like content delivery networks and e-commerce.
4. Challenges of Document Databases
Complex Relationships:
While simple relationships are easy to model, complex many-to-many relationships can be less efficient compared to relational databases.
Consistency:
Many document databases are designed with eventual consistency, which may not be suitable for applications requiring strong consistency.
Query Complexity:
Querying deeply nested or large documents can be slower compared to normalized relational structures.
Indexing Overhead:
Over-indexing can lead to increased storage requirements and slower writes.
Data Duplication:
Embedding related data can lead to duplication, increasing storage overhead and complicating updates.
5. Popular Document Databases
MongoDB:
The most widely used document database.
Features: Rich query language, sharding, aggregation framework, and flexible schema.
Example Use Case: Content management systems (CMS), real-time analytics.
Couchbase:
Combines document storage with caching for high-performance applications.
Example Use Case: Gaming leaderboards, session stores.
Amazon DocumentDB:
Fully managed document database compatible with MongoDB.
Example Use Case: Scalable e-commerce applications.
CouchDB:
Focuses on distributed applications and offline-first capabilities with synchronization.
Example Use Case: Mobile apps with offline capabilities.
6. Use Cases for Document Databases
6.1. Content Management Systems (CMS)
Why: Flexible schema allows managing diverse content types.
Example: Blog posts, product descriptions, and user-generated content.
6.2. User Profiles and Personalization
Why: Each user can have a unique set of attributes, preferences, and activity logs.
Example: Storing user preferences and purchase history in an e-commerce app.
6.3. E-Commerce Catalogs
Why: Products often have varying attributes, making schema flexibility crucial.
Example: A clothing item might have
sizeandcolor, while electronics might havespecsandwarranty.
6.4. IoT Applications
Why: IoT devices produce diverse and hierarchical data.
Example: Device metadata, sensor readings, and configurations.
6.5. Real-Time Analytics
Why: Handles high write throughput and fast reads for dashboards.
Example: Tracking user activity or clickstreams in real-time.
7. Key Considerations When Choosing Document Databases
Data Structure:
Choose document databases when the data is hierarchical, semi-structured, or unstructured.
Schema Flexibility:
Ideal for applications with frequently evolving data requirements.
Query Patterns:
Ensure query patterns can leverage document structure effectively. Overly complex queries may lead to performance bottlenecks.
Scaling Requirements:
Use for horizontally scalable applications with high read/write demands.
Consistency Needs:
Evaluate whether eventual consistency (commonly used by document databases) aligns with your application's requirements.
Deep dive into Wide column Databases
Wide column databases, also known as column-family stores, are a type of NoSQL database designed to handle large-scale, high-throughput, and low-latency data requirements. They are particularly effective for analytical workloads and use cases where the data model involves sparse, semi-structured, or high-dimensional datasets.
Core Concepts of Wide Column Databases
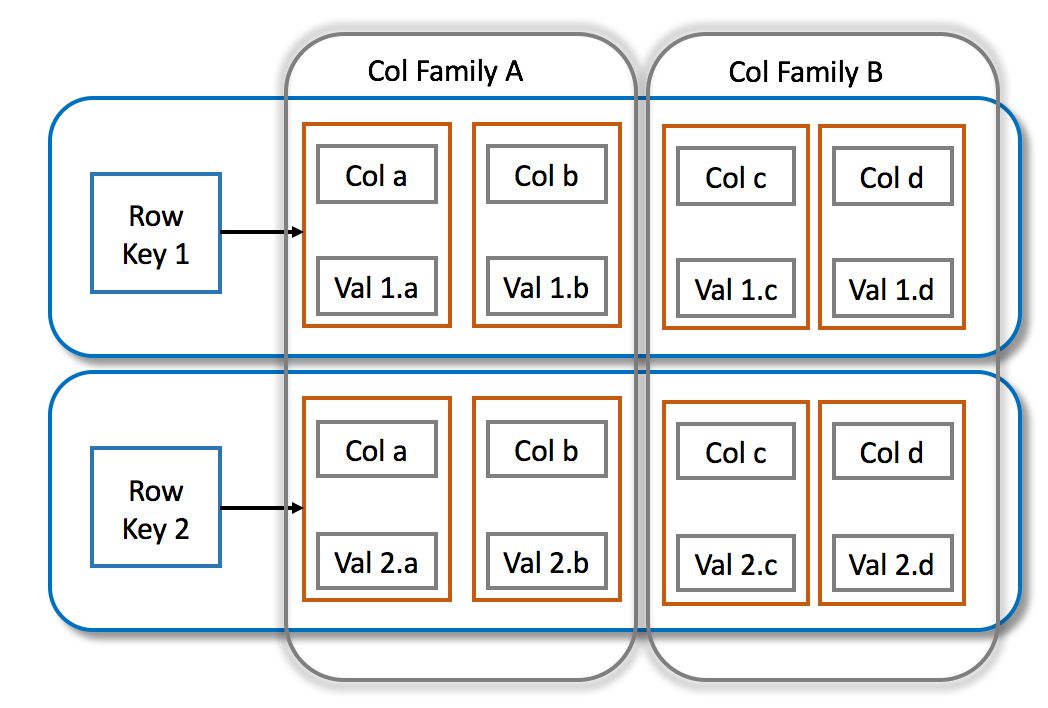
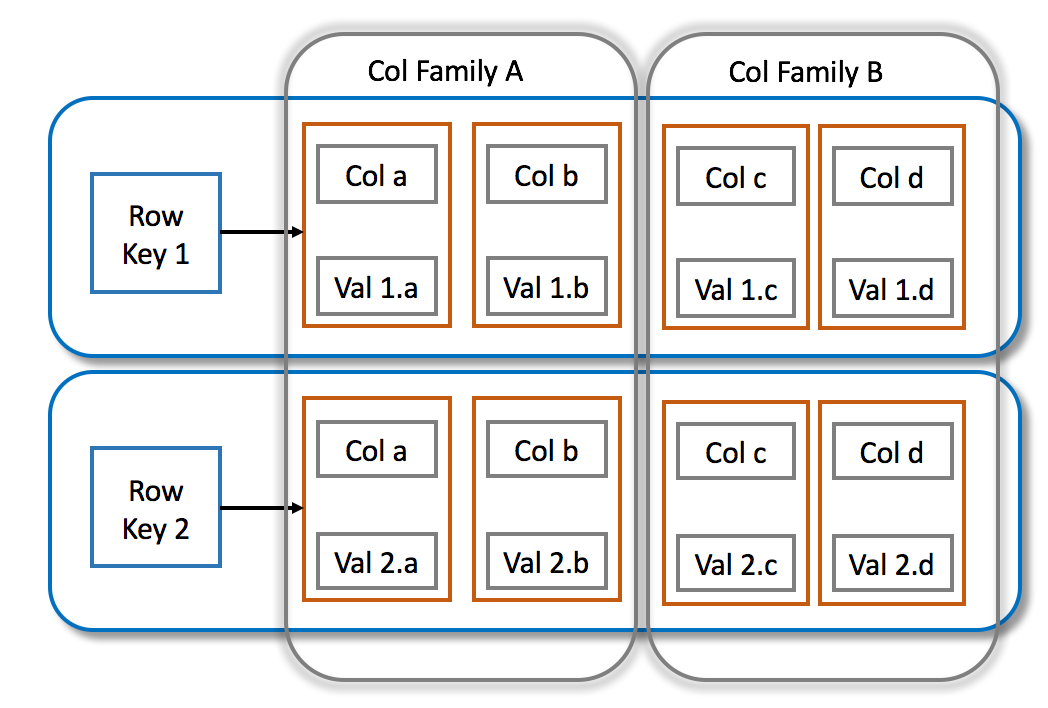
1. Column-Family Model:
Data is organized into rows and columns, similar to relational databases but with significant differences:
A row is identified by a unique row key.
Columns are grouped into column families for better organization and performance.
Each row can have a different set of columns within the same column family (schema flexibility).
2. Sparse Storage:
Wide column databases are optimized for sparse data (e.g., datasets with many missing or null values) by storing only non-empty values.
3. High Scalability:
Data is distributed across multiple nodes using sharding and partitioning, providing horizontal scalability.
4. Eventual Consistency:
Most wide column databases follow an eventual consistency model to provide high availability and partition tolerance (CAP theorem).
5. Write-Optimized:
They are optimized for write-heavy workloads, using techniques like Log-Structured Merge Trees (LSM-Trees) for efficient disk writes.
6. Time-Series Data Support:
Rows can be time-ordered, making them suitable for time-series data analysis.
Popular Wide Column Databases
Apache Cassandra:
Distributed and highly scalable.
Focused on availability and partition tolerance.
Used by companies like Netflix and Facebook.
HBase:
Built on top of Hadoop HDFS.
Integrates seamlessly with Hadoop for analytical workloads.
ScyllaDB:
A high-performance, low-latency alternative to Cassandra.
When to Use Wide Column Databases
Wide column databases are ideal for scenarios where high scalability, fast writes, and schema flexibility are critical. Below are some common use cases:
1. Time-Series Data
Why: The natural structure of wide column databases (rows with time-ordered keys) is well-suited for storing and querying time-series data.
Examples:
IoT sensor data.
Server logs and performance metrics.
Financial stock tickers.
2. High Throughput Workloads
Why: These databases are write-optimized and can handle millions of writes per second across distributed systems.
Examples:
User activity logs for real-time analytics.
Event streaming pipelines.
3. Flexible Schema Requirements
Why: Schema flexibility allows adding or removing columns without altering the overall structure.
Examples:
Content management systems.
Product catalogs with varied attributes.
4. Geo-Distributed Applications
Why: Wide column databases like Cassandra support multi-region deployments, ensuring low-latency reads and writes globally.
Examples:
Social media platforms.
Global e-commerce systems.
5. Sparse Datasets
Why: Only non-empty columns are stored, optimizing storage for datasets with many null or missing values.
Examples:
Feature stores for machine learning.
Genetic data analysis.
6. Event and Log Data
Why: The write-heavy nature and scalability are ideal for capturing and storing events in real-time.
Examples:
System logs.
Real-time monitoring and alerting systems.
7. Real-Time Recommendation Systems
Why: Efficient querying of key-value pairs and column families can support personalized recommendations.
Examples:
E-commerce product recommendations.
Video or content streaming platforms.
8. Distributed Data Workloads
Why: Horizontal scaling and replication make them robust for distributed data processing.
Examples:
Distributed ledger systems.
Telecommunication billing records.
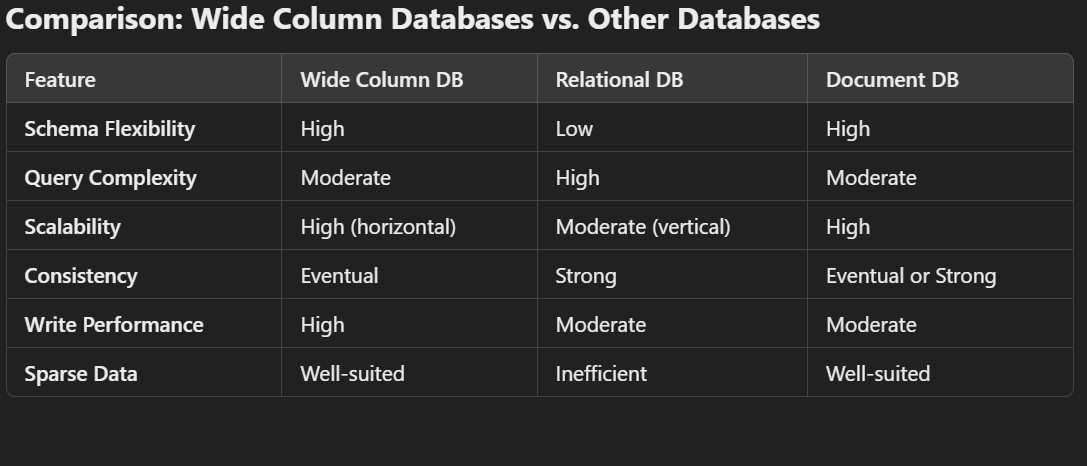
Strengths and Weaknesses
Strengths:
Horizontal Scalability: Easily scales by adding nodes.
Write Efficiency: Ideal for high-throughput, write-heavy workloads.
Schema Flexibility: Handles semi-structured data with ease.
Distributed Nature: Built for large-scale, geo-distributed systems.
Weaknesses:
Query Limitations: Not suitable for complex queries like JOINs or advanced filtering.
Eventual Consistency: May not be ideal for applications requiring strict consistency.
Learning Curve: Requires familiarity with data modeling specific to wide column databases.
Key Considerations Before Choosing Wide Column Databases
Data Access Patterns:
Optimize schema design for frequent access patterns (e.g., time-series queries, lookups by key).
Query Complexity:
Ensure queries do not require complex relationships or aggregations.
Scale Requirements:
Use for high-scale, distributed workloads with heavy write requirements.
Consistency Needs:
Eventual consistency may not suit applications like banking or critical transactions.
Data Sparsity:
Choose wide column databases for sparse datasets where only specific columns are used.
Real-World Example
Netflix:
Uses Cassandra (a wide column database) to store and query millions of user activity logs and viewing history in real-time.
Schema flexibility allows tracking different types of events with minimal changes.
Uber:
Leverages Cassandra for managing geospatial and ride data, benefiting from high write throughput and low-latency reads.
Conclusion
Wide column databases are powerful tools for handling large-scale, write-intensive, and distributed workloads with flexible schemas. They excel in scenarios requiring high availability, scalability, and real-time responsiveness, making them ideal for applications like IoT, logs, recommendations, and time-series data. However, they may not be suitable for use cases requiring complex queries or strict consistency.