
How does GitHub uses Merkel tree to compare Hashes
GitHub uses Merkle trees (a type of hash tree) in its underlying version control system, Git, to efficiently compare and verify data

Specifically, Merkle trees are utilized to represent the state of a repository at any given point in time, enabling GitHub to determine differences between commits, branches, or repositories. Here's how it works in Git/GitHub:
1. What is a Merkle Tree?
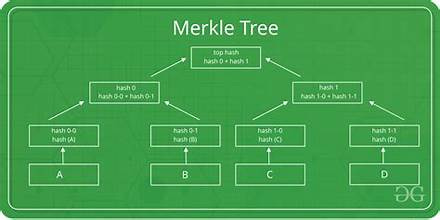
A Merkle tree is a hierarchical data structure where:
Each leaf node represents the hash of a data block (e.g., a file in a repository).
Each non-leaf node represents the hash of its child nodes (a combined hash of all data under it).
The root hash (top of the tree) represents the entire data structure.
In Git:
Every file in a repository is hashed.
Directory hashes are computed based on the hashes of their files and subdirectories.
The root of the tree represents the entire repository's state.
2. How Git Uses Merkle Trees
Git organizes the content of a repository into a Merkle tree structure:
a. Blob Objects:
Each file is stored as a blob object, and its content is hashed (SHA-1 or SHA-256, depending on the Git version).
b. Tree Objects:
Directories are stored as tree objects, which contain references to blobs (files) and other subdirectories.
Each tree object includes:
Metadata (e.g., file name, permissions).
A hash of the associated blob or subdirectory.
c. Commit Objects:
A commit object points to the root tree object, representing the entire repository's state at that commit.
Commit objects also include metadata (e.g., author, timestamp, parent commits).
3. Comparing Hashes with Merkle Trees
GitHub relies on Git's ability to compare trees using hashes. Here's how:
a. Comparing Commits
Each commit has a unique hash based on:
The hash of its root tree (repository state).
Metadata (e.g., commit message, author, and parent commit hashes).
To compare two commits, GitHub simply compares their commit hashes.
If the hashes differ, Git can traverse the tree objects to pinpoint changes.
b. Efficient Tree Comparison
Partial Tree Traversal: When comparing two repository states (trees), Git only needs to compare hashes at each level of the tree.
If the hash of a tree object is identical in both commits, Git skips its children (subtrees or files) because their content hasn't changed.
If hashes differ, Git drills down into the affected subtree(s) to locate the changes.
c. Branch and Merge Operations
When merging branches, GitHub/Git uses Merkle trees to identify the common ancestor commit (based on commit hashes) and efficiently compute differences using tree traversal.
4. Advantages of Using Merkle Trees
Efficiency:
Git avoids comparing file contents directly by using hashes, reducing I/O and computational overhead.
Changes can be localized to specific subtrees instead of the entire repository.
Integrity:
The hash of each commit is derived from its content and history, ensuring the integrity of the repository's state.
Incremental Updates:
When a file changes, only the hashes of the affected file, its parent directories, and the root tree need to be updated.
5. Practical Example
Consider comparing two commits, A and B:
Git compares the root tree hashes of
AandB.If they differ, Git traverses into the subtrees:
For each subtree or file, Git compares hashes.
If a hash matches, it skips further traversal for that part of the tree.
If a hash differs, it identifies the changes in the corresponding files or subdirectories.
GitHub displays the differences (e.g., changed files, added/deleted lines) in its user interface.
In essence, GitHub leverages Git's Merkle tree structure to perform efficient, hash-based comparisons, enabling it to scale for large repositories and provide rapid feedback on changes.
source:-wikipedia