
How does Glue Catalog can improve overall architecture in databases
AWS Glue Catalog is a centralized metadata repository for managing and organizing datasets in your data lake or data ecosystem

It provides a unified view of your data assets and can significantly enhance the overall database architecture by addressing challenges like data discoverability, schema management, and integration. Here's how it can improve the overall architecture:
1. Centralized Metadata Management
Problem: In large-scale systems, metadata (e.g., schemas, table definitions, locations) is often fragmented across various databases and storage solutions.
Glue Catalog Solution:
Acts as a central repository for metadata, enabling a unified view across diverse data sources.
Integrates with databases, data lakes, and analytics tools, making it easier to discover and manage datasets.
2. Schema Evolution and Management
Problem: Schema changes, such as adding new columns or changing data types, can disrupt downstream applications.
Glue Catalog Solution:
Tracks schema versions, allowing applications to handle schema evolution gracefully.
Provides tools for automatic schema inference and validation, reducing manual intervention.
3. Integration with Diverse Data Sources
Problem: Managing metadata for heterogeneous systems (e.g., relational databases, NoSQL databases, data lakes) can be complex.
Glue Catalog Solution:
Supports integration with databases like Amazon Redshift, RDS, DynamoDB, and S3-based data lakes.
Ensures consistent metadata access across multiple systems.
4. Query and Data Discoverability
Problem: Discovering datasets across a distributed environment can be time-consuming and inefficient.
Glue Catalog Solution:
Enables data discovery using a consistent interface (e.g., via AWS Athena, EMR, or Redshift Spectrum).
Allows users to search for datasets by metadata attributes (e.g., table name, columns, tags).
5. Security and Governance
Problem: Maintaining data access control and governance policies across multiple systems is challenging.
Glue Catalog Solution:
Integrates with AWS Lake Formation for fine-grained access control.
Provides role-based access management for datasets, ensuring compliance with security policies.
Audits data usage and access patterns through integrated logging.
6. Enhances ETL Workflows
Problem: Building and managing ETL pipelines for large-scale systems often requires significant effort in schema management and transformations.
Glue Catalog Solution:
Simplifies ETL workflows by providing metadata that ETL tools can directly leverage.
AWS Glue ETL jobs automatically use the catalog for schema definitions and transformations.
Reduces redundancy and errors in data processing pipelines.
7. Enables Data Federation
Problem: Accessing data across multiple storage systems without moving it can be challenging.
Glue Catalog Solution:
Allows federated queries across multiple data sources via tools like AWS Athena and Redshift Spectrum.
Leverages the Glue Catalog to provide unified metadata for data residing in various locations.
8. Performance Optimization
Problem: Query performance can degrade without optimized metadata or partitioning.
Glue Catalog Solution:
Facilitates partitioning of datasets for faster queries.
Integrates with tools like Athena and EMR to optimize query execution plans using catalog metadata.
9. Data Lineage and Observability
Problem: Understanding data lineage and dependencies in complex systems can be cumbersome.
Glue Catalog Solution:
Tracks data lineage and dependencies between datasets, helping identify the impact of changes.
Provides observability into metadata changes and access patterns.
10. Cost Efficiency
Problem: Data duplication and inefficient data processing workflows can lead to higher costs.
Glue Catalog Solution:
Minimizes data duplication by providing a single source of truth for metadata.
Reduces manual effort in managing schemas, saving time and resources.
Use Cases of Glue Catalog in Database Architecture
Data Lake Management:
Organize and manage metadata for datasets in S3-based data lakes.
Enable analytics tools like Athena and EMR to query data efficiently.
Hybrid Database Ecosystems:
Serve as a bridge between on-premises databases and cloud-based systems by centralizing metadata.
Data Analytics Pipelines:
Streamline ETL workflows with schema discovery and validation.
Allow seamless integration of analytics platforms like QuickSight or Tableau.
Governance and Compliance:
Ensure datasets meet regulatory requirements by managing metadata and access policies centrally.
Challenges Glue Catalog Solves
Scattered metadata across systems: Brings all metadata into a unified catalog.
Manual schema management: Automates schema discovery and management.
Data access bottlenecks: Provides seamless access to datasets across sources.
Security and compliance risks: Centralized governance improves compliance.
Conclusion
AWS Glue Catalog improves database architecture by simplifying metadata management, enhancing integration, and enabling scalability and governance. It acts as the backbone for modern data platforms, supporting seamless data discovery, query optimization, and integration across diverse systems while reducing operational complexity.
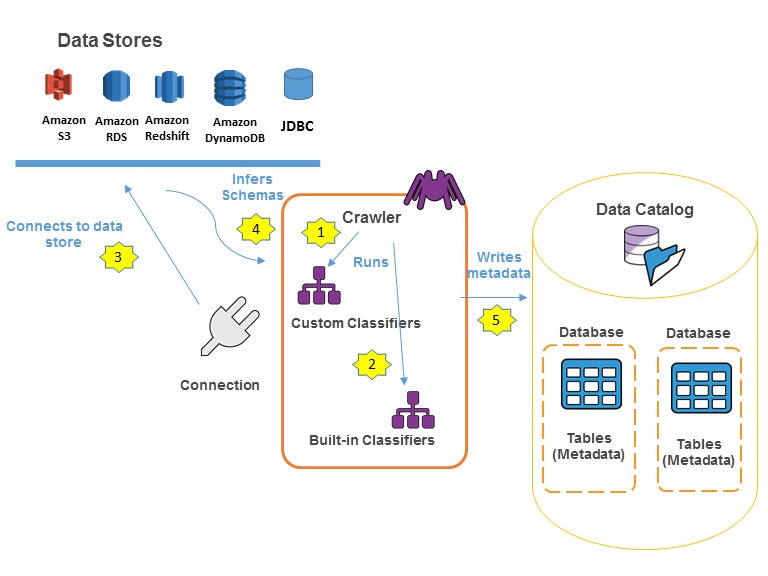
Image source:-wikipedia