
How does replica know it has to fetch data from logs of master in Leader based databases like SQL?
The replica knows it has to fetch data from the logs of the primary (master) through a configured replication mechanism that relies on the binary logs (or equivalent) generated by the primary

Here's how the process works step-by-step:
1. The Primary (Master) Writes Binary Logs
The primary records all database changes (INSERT, UPDATE, DELETE, etc.) in its binary logs.
These binary logs contain:
SQL statements (in Statement-Based Replication, SBR).
Row-level changes (in Row-Based Replication, RBR).
Transaction boundaries (e.g.,
BEGIN,COMMIT).
The binary logs are stored sequentially, and each entry has:
A log position (byte offset).
A timestamp.
Event details (e.g., table name, operation type, row changes).
2. Replica Configuration
The replica must be explicitly configured to communicate with the primary. This involves:
Pointing the Replica to the Primary:
You provide the replica with the following information:
Primary's Host Address: The IP/hostname of the primary database.
Port: The port where the primary database is running (default for MySQL is 3306).
Replication User Credentials: A username and password that allows the replica to access the primary's binary logs. (This is set up on the primary with
GRANT REPLICATION SLAVE.)
CHANGE MASTER TO
MASTER_HOST='primary_host',
MASTER_PORT=3306,
MASTER_USER='replica_user',
MASTER_PASSWORD='replica_password',
MASTER_LOG_FILE='binlog.000001',
MASTER_LOG_POS=120;
Replica Starts the Replication Process:
On the replica, you start the replication process with a command like
START SLAVE;The replica begins fetching binary logs from the primary.
3. How the Replica Fetches Logs
The replica communicates with the primary via a replication thread.
IO Thread on the Replica:
The replica starts an I/O thread, which connects to the primary and requests binary logs starting from a specific log file and position.
For example, if the replica last processed
binlog.000001at position120, it will request the logs from that point onward.
Primary Sends Logs:
The primary reads its binary logs and sends the requested log events to the replica.
Relay Logs on the Replica:
The replica writes the received binary log events into its relay logs (a local copy of the primary's binary logs).
The relay logs ensure that even if the replication process is interrupted, the replica can resume processing without re-requesting logs from the primary.
SQL Thread on the Replica:
The replica's SQL thread reads the relay logs and applies the log events to its local database.
This is where the actual data changes (e.g., INSERTs, UPDATEs, DELETEs) are applied to make the replica consistent with the primary.
4. Mechanism to Keep Track of Logs
The replica maintains state information to know what binary logs and log positions it has already processed.
Master Log File and Position:
The replica keeps track of the binary log file and the byte offset (position) it has processed so far.
Master_Log_File = binlog.000002 Read_Master_Log_Pos = 54321
Persistence of State:
This information is stored in the replica's metadata or database files.
Even if the replica restarts, it knows where to resume fetching logs from the primary.
Replication Heartbeat:
The primary and replica exchange heartbeat signals to ensure the replica stays synchronized and doesn't miss logs.
5. Continuous Log Fetching
The replica continuously fetches new log events from the primary in near real-time.
If the replica falls behind (e.g., due to network issues or heavy load), it resumes fetching logs from the last known position.
6. Example
Let’s say the primary has the following binary log entries:
Primary Binary Logs (binlog.000001):
Position 120: INSERT INTO employees VALUES (1, 'Alice', 50000);
Position 200: UPDATE employees SET salary = 60000 WHERE id = 1;
Position 300: DELETE FROM employees WHERE id = 2;
The replica starts with:
Master_Log_File = binlog.000001
Read_Master_Log_Pos = 120
The replica fetches:
Logs starting from position
120.Applies the changes (
INSERT,UPDATE,DELETE) locally.
After processing, the replica updates its position to:
Master_Log_File = binlog.000001 Read_Master_Log_Pos = 300
How Replication Handles Failures
Network Issues:
If the replica loses connection to the primary, it resumes replication from the last known position when the connection is restored.
Primary Crash:
If the primary crashes, the replica cannot fetch logs until the primary is back online or promoted from backups.
Replica Crash:
If the replica crashes, it restarts replication from its last processed log position.
Key Takeaways
The replica fetches binary logs from the primary by continuously requesting them over a replication thread.
The replication process ensures the replica knows where to start by maintaining a log file name and position.
Replication is an asynchronous process, meaning there can be a slight delay between the primary and replica.
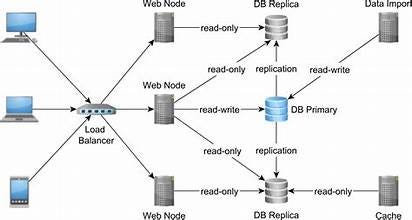
source :- wikipedia