
How to get rid of Deadlocks in a large scale system.
Eliminating deadlocks in a large-scale system requires a multi-pronged approach. Here are some strategies:

Consistent Lock Ordering:
Design a global order for acquiring locks. Ensure that every process or thread requests locks in the same order, which can prevent circular wait conditions.
Timeouts and Lock-Free Techniques:
Implement timeouts when acquiring locks. If a process waits too long, it can release its held resources and retry, reducing the chance of a deadlock.
Use lock-free or non-blocking algorithms where possible to avoid holding locks altogether.
Deadlock Detection and Recovery:
Monitor the system with a wait-for graph to detect cycles that indicate deadlocks.
Once detected, selectively roll back or abort one of the processes to break the cycle.
Resource Hierarchy and Granularity:
Organize resources in a hierarchy. This ensures that a process holding a lower-level resource won’t request a higher-level resource.
Minimize the scope and duration of critical sections to reduce the window where deadlocks might occur.
Optimistic Concurrency Control:
Allow concurrent operations without locking and perform conflict detection at commit time. If a conflict is found, roll back the transaction.
Some additional insights and techniques that build upon the strategies mentioned above
1. Consistent Lock Ordering
Central Coordination:
In distributed systems, you might employ a centralized or distributed lock manager (e.g., ZooKeeper, etcd, or Consul) that enforces a global lock ordering. This can help coordinate resource access across different nodes.Granularity of Locks:
Consider whether coarse-grained or fine-grained locking is more appropriate. Fine-grained locks can reduce contention but may increase complexity in managing the order.Example:
Imagine you have resources A, B, and C. Always acquire locks in the order A → B → C. If a process needs A and C, it still must acquire A before C to prevent circular waiting.
2. Timeouts and Lock-Free Techniques
Adaptive Timeouts:
Tune timeouts based on system load. For example, during high load, slightly longer timeouts might be necessary to allow transactions to complete, whereas shorter timeouts can be used during low load to quickly detect potential deadlocks.Non-blocking Algorithms:
Where possible, leverage lock-free data structures (using atomic operations like CAS) or design parts of the system to be lock-free. This reduces reliance on locks and minimizes deadlock risk.Optimistic Concurrency:
Implement optimistic concurrency control where processes proceed without locks and validate their actions at commit time. If a conflict is detected, the transaction is rolled back and retried.
3. Deadlock Detection and Recovery
Wait-for Graphs in Distributed Environments:
In large-scale systems, you might need to aggregate local wait-for graphs into a global view. This can be challenging but is feasible with tools designed for distributed tracing and monitoring.Recovery Policies:
Once a deadlock is detected, you can choose a victim process to roll back based on criteria like resource usage, priority, or the cost of aborting a transaction. This selective rollback helps resolve deadlocks with minimal disruption.Automated Recovery:
Consider integrating automated recovery procedures that not only detect deadlocks but also resolve them with minimal human intervention.
4. Resource Hierarchy and Granularity
Hierarchical Resource Management:
Define a clear hierarchy among resources. For example, in a multi-tiered application, locks on higher-level resources (like session management) should always be acquired before lower-level resources (like individual data items).Reducing Lock Duration:
Design your transactions to hold locks for the shortest duration possible. This minimizes the window during which other processes can get blocked, thereby reducing deadlock probability.
5. Optimistic Concurrency Control
Multi-Version Concurrency Control (MVCC):
Use MVCC to allow multiple versions of data, which lets read operations occur without blocking write operations. This is especially useful in database systems to reduce conflicts.Conflict Detection and Resolution:
Implement robust conflict detection mechanisms that can efficiently detect when a transaction needs to be rolled back. Fine-tuning these algorithms can help balance performance with consistency.
Additional Techniques
Avoid Hold-and-Wait:
Request all required locks at the beginning of a transaction rather than acquiring them incrementally. This reduces the chance of a process holding one lock while waiting for another.Prevention Protocols:
Wait-Die and Wound-Wait Algorithms:
These are age-based schemes where older transactions can force younger ones to abort (wound-wait) or wait (wait-die), reducing circular waiting.
Testing and Simulation:
Incorporate rigorous stress testing and simulation of potential deadlock scenarios in your test environments. Tools that simulate high concurrency can reveal subtle deadlock conditions before they occur in production.Monitoring and Logging:
Enhance your system's observability with detailed monitoring and logging. Real-time metrics and logs can help you quickly spot patterns that might lead to deadlocks.Distributed Coordination Tools:
Leverage coordination tools like Apache ZooKeeper or etcd not only for lock management but also for health checking and leader election, which can further help in preventing resource contention.
Summary
In large-scale systems, eliminating deadlocks is less about a one-size-fits-all solution and more about a blend of proactive design and reactive recovery. Combining strict lock ordering, adaptive timeouts, efficient deadlock detection, and using optimistic concurrency can significantly reduce the risk. Regular testing and monitoring, coupled with modern distributed coordination tools, round out an effective strategy to manage and resolve deadlocks.
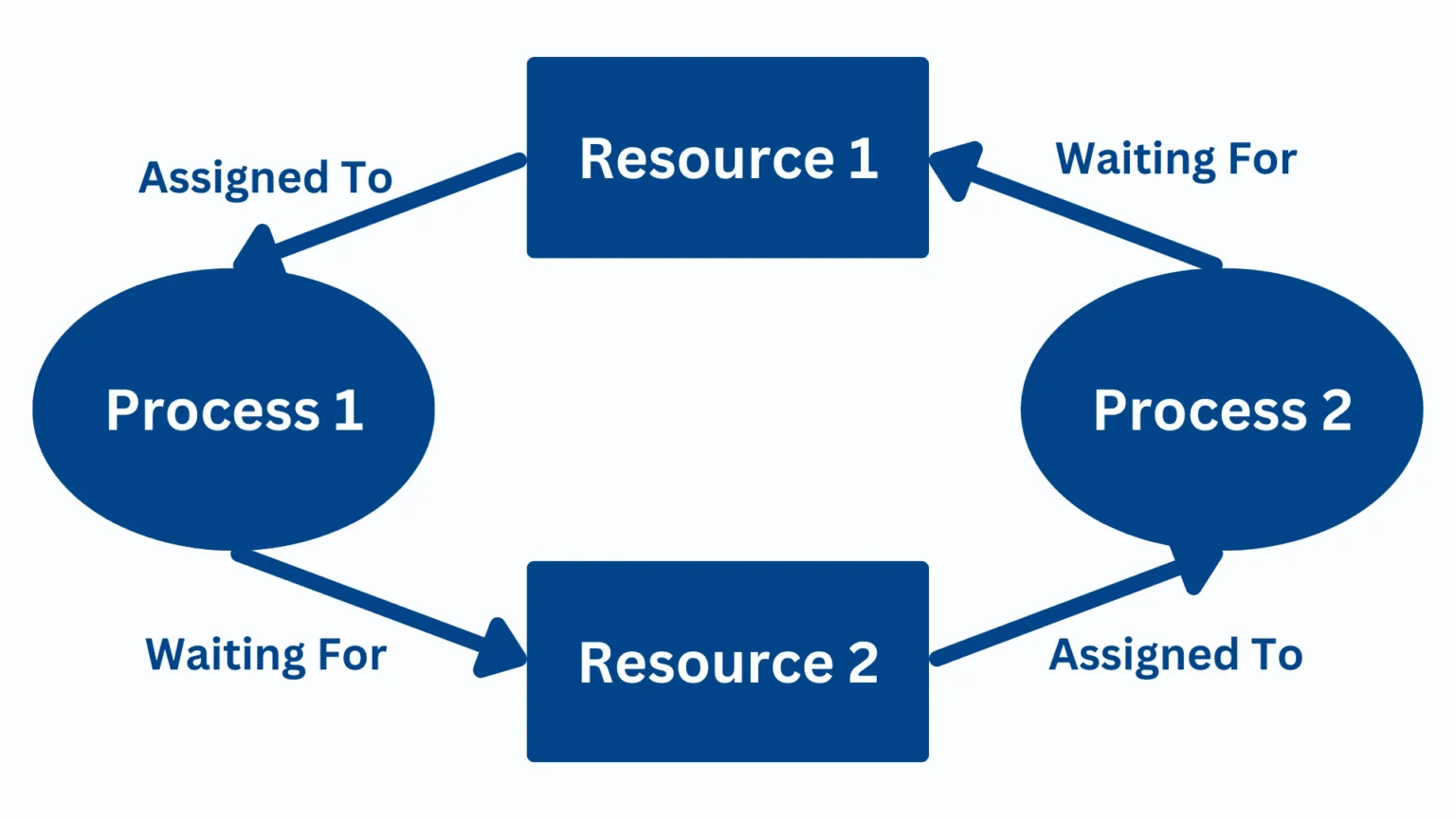
Image Source:-wikipedia