Identify K most shared articles between various time windows (like 24 hrs,5hrs,1hr,5 minutes)
Let's look into functional requirements

FR
1.Maintain a record of each article being shared.
2.Retrieve the top K most shared articles in various time windows:
3.Articles should be ranked by share count within the selected time window.
4.The system should support real-time updates as new shares happen.
NFRs
1.System should have low latency for queries to get top K most shared articles should within <100ms
2.System should be highly scalable to support millions of share events per minute.
3.Use time-windowed aggregations instead of scanning all records.
4.System should be highly available even under high traffic.
5.System should be fault tolerant to ensure no data loss in case of node failures.
6.System should be eventual consistent for real-time processing is expensive, allow minor delays (e.g., a few seconds) while ensuring correctness.
Back of envelope calculation
Total active users: 500M
Shares per user per day: 5 (on average)
total shares per day = 5*500M=2500M
QPS=500M/10^5=5k QPS
Peak write rate: 10x average traffic
For peak= 5k*10=50k
Storage retention: 24 hours (for real-time rankings)
article_id (8 bytes)
user_id (8 bytes)
timestamp (8 bytes)
total= 24 bytes
For storage=2500M*30Bytes(approximating 24 bytes)=75000Mbytes=75M(KB)=75GBAPI’s
Logs when a user shares an article.
1.POST /api/v1/articles/{article_id}/share
request {
"user_id": "12345",
"timestamp": "2025-03-28T14:25:00Z"
}
response {
"message": "Share recorded successfully",
"article_id": "article_987",
"timestamp": "2025-03-28T14:25:00Z"
}
2.Fetches the top K most shared articles within a given time window.
GET /api/v1/articles/top-shared
GET /api/v1/articles/top-shared?window=1h&k=10
{
"window": "1h",
"top_articles": [
{ "article_id": "article_123", "shares": 1050 },
{ "article_id": "article_456", "shares": 987 },
{ "article_id": "article_789", "shares": 765 }
]
}
3.Fetches the total number of shares for a given article.
GET /api/v1/articles/{article_id}/shares
{
"article_id": "article_987",
"total_shares": 12500
}
Database Schema
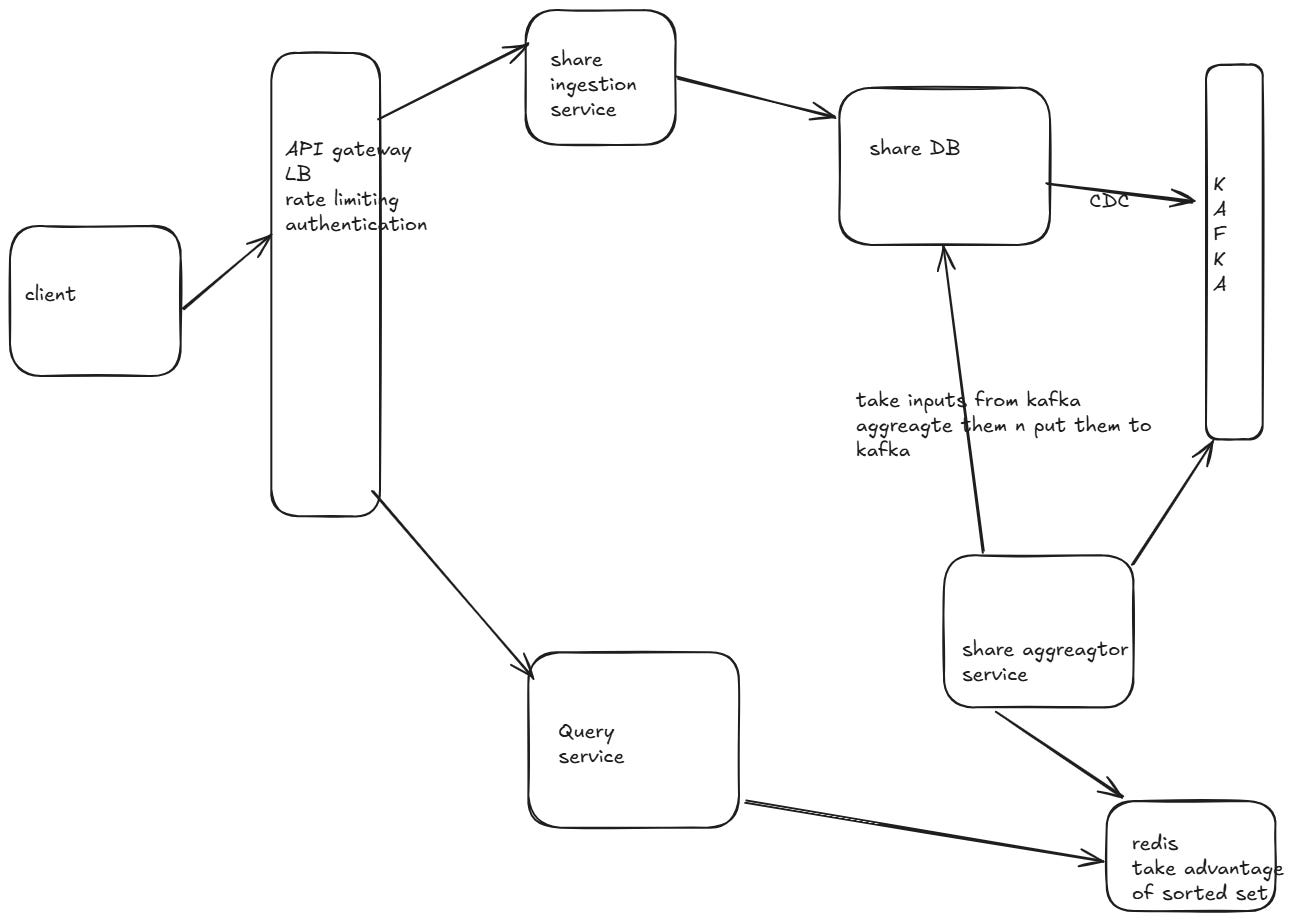
2️⃣ Database Schema Design
🔹 (A) Kafka (Event Stream)
✅ Why?
Acts as an ingestion pipeline, handling millions of events per second.
Streams data to Cassandra, Redis, and Flink/Spark for processing.
✅ Schema (Message Format)
{
"event_id": "uuid-12345",
"article_id": "article_987",
"user_id": "user_12345",
"timestamp": "2025-03-28T14:25:00Z"
}
🔹 (B) Cassandra / DynamoDB (Persistent Storage for Share Events)
✅ Why?
Handles high write throughput (millions of inserts/sec).
TTL support to automatically expire old data (>24h).
Can be partitioned by time + article_id for fast lookups.
✅ Schema (Table: article_shares)
CREATE TABLE article_shares (
article_id TEXT,
share_time TIMESTAMP,
share_count COUNTER,
PRIMARY KEY ((article_id), share_time)
) WITH CLUSTERING ORDER BY (share_time DESC)
AND default_time_to_live = 86400; -- Expire data after 24h
✅ How it works?
Uses COUNTER type for incrementing share counts.
Time-based partitioning ensures efficient queries for time windows (e.g., last 5m, 1h, 24h).
🔹 (C) Redis Sorted Sets (Top-K Shared Articles)
✅ Why?
Fast O(log N) ranking queries using Sorted Sets (
ZSET).Stores rolling counts for 5m, 1h, 5h, 24h windows.
✅ Schema (ZSET per time window)
ZINCRBY top_articles_1h 1 "article_987"
ZINCRBY top_articles_24h 1 "article_123"
✅ Query for Top-K
ZRANGE top_articles_1h 0 9 WITHSCORES -- Get top 10 shared articles in 1h
🔹 (D) ClickHouse / BigQuery (Historical Analytics - Optional)
✅ Why?
If long-term analytics (trends beyond 24h) are needed.
Columnar storage allows fast aggregations.
✅ Schema (Table: article_share_history)
CREATE TABLE article_share_history (
article_id String,
share_time DateTime,
total_shares UInt64
) ENGINE = MergeTree()
ORDER BY (share_time, article_id);
✅ Query Example
SELECT article_id, SUM(total_shares)
FROM article_share_history
WHERE share_time >= now() - INTERVAL 7 DAY
GROUP BY article_id
ORDER BY SUM(total_shares) DESC
LIMIT 10;
HLD