Summary of paper Large -cluster management at Google with Borg
Recently was skimming through the paper ,thought of summarizing over here

The paper, "Large-Scale Cluster Management at Google with Borg", describes Borg, Google's cluster management system, which efficiently manages jobs across thousands of machines in Google's data center
Borg is the precursor to Kubernetes and has influenced modern container orchestration systems.
1. Key Goals of Borg
High Utilization:
Maximize resource utilization across clusters.
Reliability:
Ensure applications are resilient to failures of nodes or components.
Scalability:
Support thousands of nodes and millions of jobs.
Efficiency:
Schedule and manage both latency-sensitive (e.g., web services) and batch-processing workloads.
Operational Flexibility:
Enable rapid development and deployment of applications.
2. Architecture
Borg has a centralized architecture with key components:
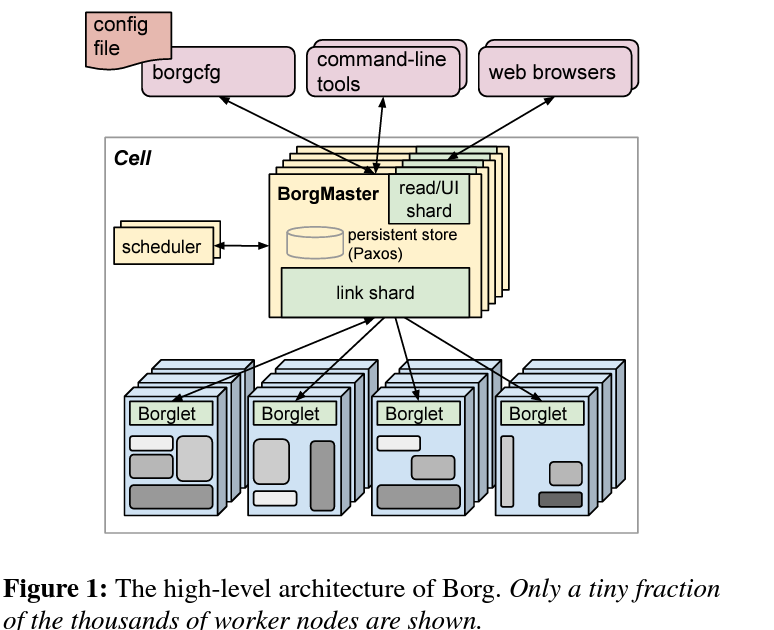
2.1 Borgmaster
The central controller responsible for:
Scheduling jobs.
Managing cluster state.
Handling communication with worker nodes.
2.2 Borglets
Agents running on each machine (similar to Kubernetes kubelet).
Responsible for:
Monitoring and managing tasks.
Reporting resource utilization to the Borgmaster.
2.3 State Management
Borgmaster maintains the cluster state using highly available, distributed storage.
Supports durability and consistency.
3. Features
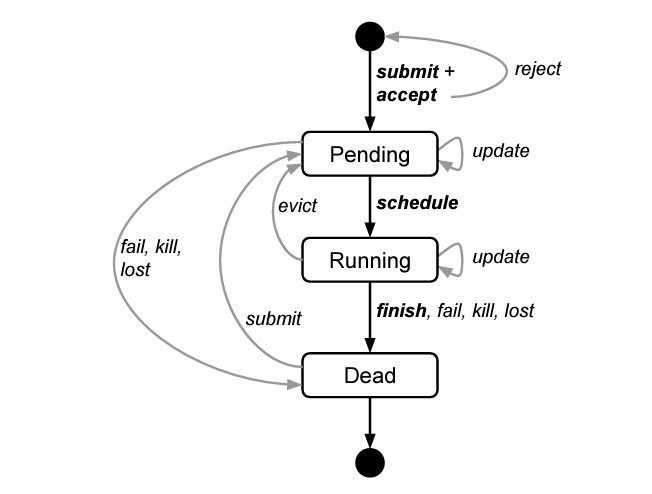
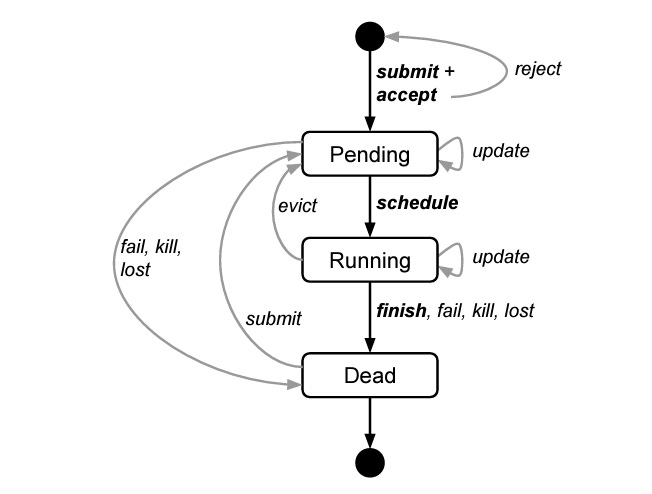
3.1 Scheduling
Two-Pass Scheduler:
First Pass: Quickly finds a feasible placement for tasks based on resource constraints.
Second Pass: Optimizes placements to improve resource utilization and reduce fragmentation.
Supports priority-based scheduling:
Higher-priority jobs (e.g., user-facing services) preempt lower-priority ones.
3.2 Resource Allocation
Tracks CPU, memory, disk, and network resources for efficient allocation.
Prevents over-commitment of resources while maximizing usage.
3.3 Failure Handling
Detects and mitigates failures through:
Replication.
Automatic restarts of failed tasks.
Load balancing across healthy nodes.
3.4 Containers
Borg uses lightweight process-level containers to isolate tasks (precursor to Docker and Kubernetes containers).
Ensures resource isolation and security.
4. Workload Types
Borg supports two primary workloads:
Production Workloads:
Latency-sensitive jobs, like Google's web search.
Assigned higher priority and guaranteed resources.
Batch Workloads:
Non-latency-sensitive jobs, like MapReduce or analytics.
Utilize leftover capacity, improving cluster efficiency.
5. Design Principles
Centralized Control: Single point of control for scheduling and cluster state.
Optimizing Utilization: Balancing between high-priority production tasks and low-priority batch jobs.
Preemption: Higher-priority tasks can preempt lower-priority ones if resources are scarce.
Fault Tolerance: Built-in mechanisms for detecting and recovering from hardware and software failures.
6. Challenges Addressed
Scalability:
Borg manages clusters with tens of thousands of machines and millions of tasks.
Resource Fragmentation:
Intelligent scheduling reduces fragmentation, maximizing utilization.
Fault Tolerance:
Automated recovery and replication minimize the impact of node failures.
7. Influence on Kubernetes
Many concepts in Kubernetes were inspired by Borg:
Pod abstraction: Based on Borg’s task grouping.
Declarative API: Similar to Borg’s configuration language.
Schedulers and resource isolation: Refined from Borg’s design principles.
8. Key Takeaways
Borg demonstrated that centralized, container-based cluster management is practical and scalable.
It set the foundation for modern orchestration systems like Kubernetes and Apache Mesos.
Its lessons in fault tolerance, resource management, and workload diversity are still relevant today.
Source:- From paper itself
Some more deep dives
1. Scheduling: The Two-Pass Scheduler
The Two-Pass Scheduler in Borg is a standout feature, showcasing a balance between speed and optimization:
1.1 First Pass: Feasibility Check
The scheduler quickly determines a feasible placement for the task based on resource availability.
Focus: Speed. It avoids spending excessive time optimizing placements when a simple fit would suffice.
Filters nodes using:
Resource constraints (e.g., CPU, memory).
Affinity/anti-affinity rules (e.g., tasks that must run together or apart).
Zone constraints (to distribute tasks across failure zones).
1.2 Second Pass: Optimization
After placement, the second pass works to improve resource utilization and reduce fragmentation by:
Relocating tasks to consolidate free space.
Balancing tasks across machines to prevent hotspots.
1.3 Preemption
If higher-priority tasks arrive, they can preempt lower-priority ones already scheduled.
Preempted tasks are rescheduled elsewhere or paused temporarily.
This ensures that critical production workloads are always prioritized.
This dual scheduling approach balances:
Speed for immediate task placement.
Optimization for long-term resource efficiency.
2. Resource Allocation and Isolation
Borg was among the first systems to utilize lightweight process containers (predecessors to Docker) to achieve:
Resource Isolation:
CPU, memory, disk, and network resources are allocated per task.
Tasks are prevented from interfering with each other (e.g., one task over-consuming memory won't crash others).
Efficiency:
Containers allow tasks to share the same OS while isolating resources.
Low-overhead compared to full virtual machines.
Borg’s containerization principles directly influenced the creation of modern container technologies like Docker and Kubernetes.
2.1 Overcommitment
While resources are strictly allocated for high-priority tasks, batch tasks can utilize leftover capacity.
If production jobs later require those resources, batch tasks are preempted or throttled.
2.2 Handling Fragmentation
Resource fragmentation (e.g., small unusable chunks of CPU or memory) is reduced through:
Compacting tasks onto fewer nodes.
Intelligent scheduling that packs jobs efficiently.
3. Fault Tolerance
Borg assumes that failures are inevitable in large-scale systems. Its architecture includes mechanisms for detecting and recovering from failures:
3.1 Automated Recovery
Node Failures:
Borglets on each node regularly report their health to the Borgmaster.
If a node becomes unresponsive or fails, tasks running on it are automatically rescheduled on healthy nodes.
Task Failures:
Failed tasks are restarted, either on the same machine or a different one, based on resource availability.
3.2 Replication and Redundancy
For high-priority jobs, Borg supports task replication across multiple nodes or zones.
This redundancy ensures continued availability, even if a node or entire data center zone fails.
3.3 State Persistence
Borgmaster maintains the cluster state in a distributed, persistent storage system.
This enables recovery of the Borgmaster itself in case of failure, minimizing downtime.
4. Workload Diversity
Borg handles a mix of latency-sensitive production jobs and batch-processing jobs on the same cluster:
4.1 Production Jobs
High-priority jobs like Google Search or Gmail are latency-sensitive and require:
Guaranteed resource allocation.
Low tail latencies to maintain user experience.
4.2 Batch Jobs
Batch jobs (e.g., analytics, MapReduce) have lower priority and use leftover capacity.
Borg uses opportunistic scheduling for these jobs:
They run when and where resources are available.
They can be paused or preempted if high-priority jobs require resources.
4.3 Priority-Based Scheduling
Each job is assigned a priority level.
The scheduler always prioritizes higher-priority jobs.
This mechanism ensures that critical tasks are unaffected by less important ones.
5. Scalability
Borg scales to clusters with:
Tens of thousands of machines.
Millions of tasks running concurrently.
5.1 Challenges Overcome
Centralized Control:
While centralized architectures are often bottlenecks, Borg uses optimizations to scale its Borgmaster.
The Borgmaster handles scheduling and state management for the entire cluster, but the workload is distributed through components like link shards.
Efficient State Management:
Borgmaster keeps cluster state in distributed storage, ensuring consistency and fault tolerance.
Link shards partition communication, offloading direct communication from the Borgmaster.
6. Production-Grade Engineering
Borg prioritizes operational simplicity for its users:
Engineers can define jobs using a declarative configuration language:
Specifies tasks, resource requirements, priorities, and failure handling policies.
Borg abstracts away complexities like fault tolerance and scaling, allowing users to focus on their applications.
6.1 Observability
Borg provides comprehensive monitoring and logging capabilities:
Engineers can track resource usage, task statuses, and failures in real-time.
Debugging tools help identify and resolve issues efficiently.
6.2 Debugging
Borg lets engineers "peek" into running tasks, making it easier to debug production issues without disrupting the cluster.
7. Influence on Modern Systems
Borg was the blueprint for modern container orchestration systems like Kubernetes. Key concepts inherited by Kubernetes include:
Pods: Kubernetes’ fundamental scheduling unit is inspired by Borg’s grouping of tasks.
Declarative Configurations: Kubernetes' YAML manifests are based on Borg’s configuration files.
Fault Tolerance: Both systems assume failures are common and handle them gracefully.
Priority Preemption: Kubernetes inherited the ability to preempt low-priority pods.
8. Challenges in Borg
Despite its success, Borg faced challenges:
Centralization:
The centralized Borgmaster is a single point of failure, although mitigated by replication and state persistence.
Complexity:
Borg’s internal architecture is sophisticated, requiring significant expertise to manage and operate.
Legacy:
Over time, adapting Borg to evolving workloads and technologies (e.g., machine learning) became challenging.
Source:- From paper itself