What is chain replication in databases
Chain replication is a replication strategy used in distributed databases and storage systems to ensure fault tolerance and strong consistency.

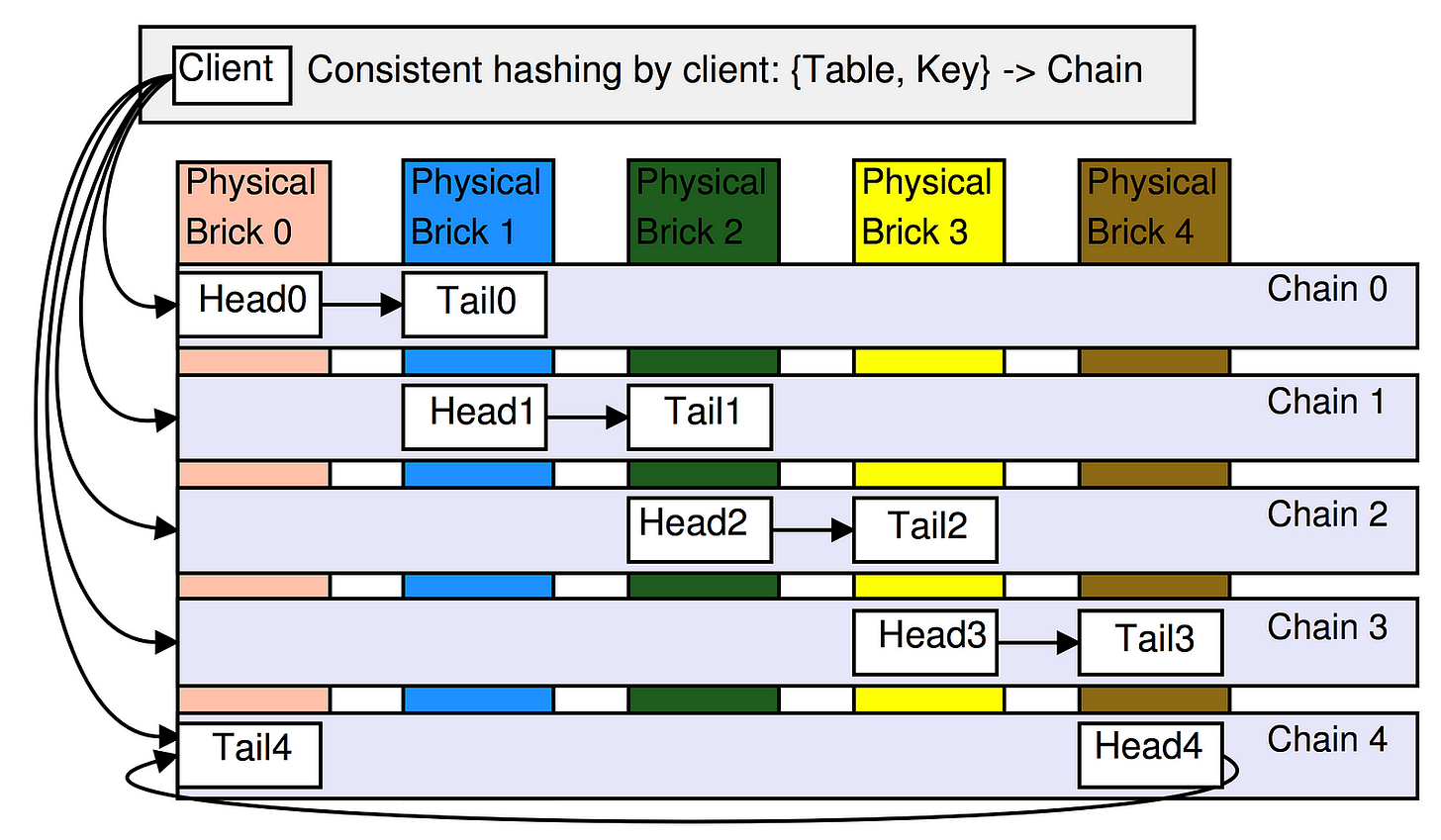
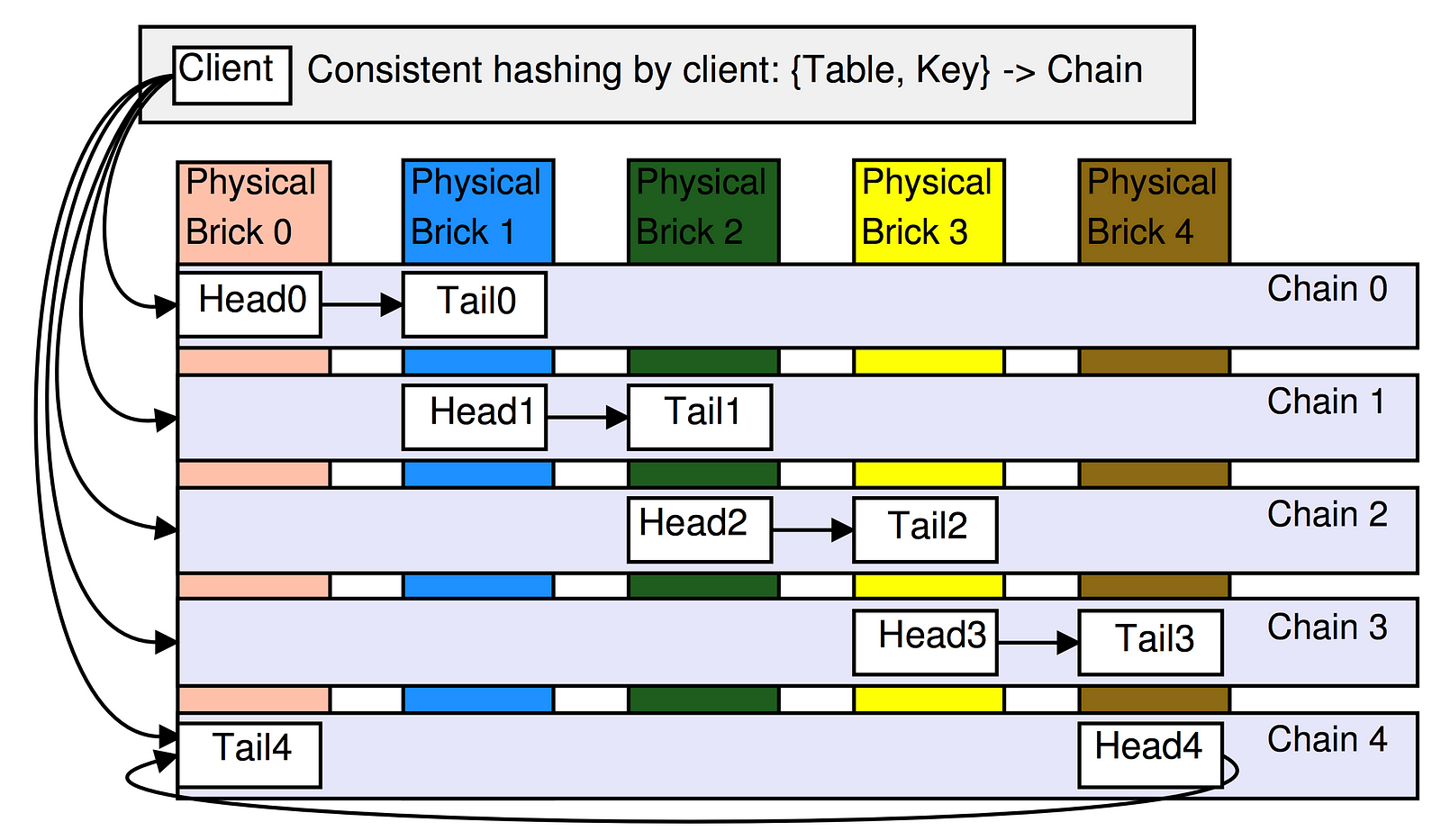
It organizes database nodes into a linear chain, where each node replicates data from the previous node and forwards writes to the next node in the chain. Reads and writes follow specific rules depending on the position of the nodes in the chain.
Key Concepts of Chain Replication
Linear Node Arrangement:
Nodes are arranged in a sequential order (like a chain).
The chain has a head, tail, and intermediate nodes:
Head: First node in the chain, responsible for accepting write requests.
Tail: Last node in the chain, responsible for servicing read requests.
Intermediate Nodes: Pass data from head to tail while maintaining consistency.
Write Operations:
Writes are sent to the head of the chain.
The head processes the write and forwards it to the next node in the chain.
This continues until the write reaches the tail, ensuring that all nodes in the chain have the updated data.
Once the tail confirms the write, the write operation is considered complete.
Read Operations:
Reads are serviced by the tail of the chain, ensuring that the data read is always consistent and up-to-date.
This is because the tail has the latest version of the replicated data.
Fault Tolerance:
If a node fails:
A new chain is formed by excluding the failed node.
In the case of the head or tail failing, the next node in the sequence becomes the new head or tail, respectively.
The system can recover by re-replicating the lost data from surviving nodes.
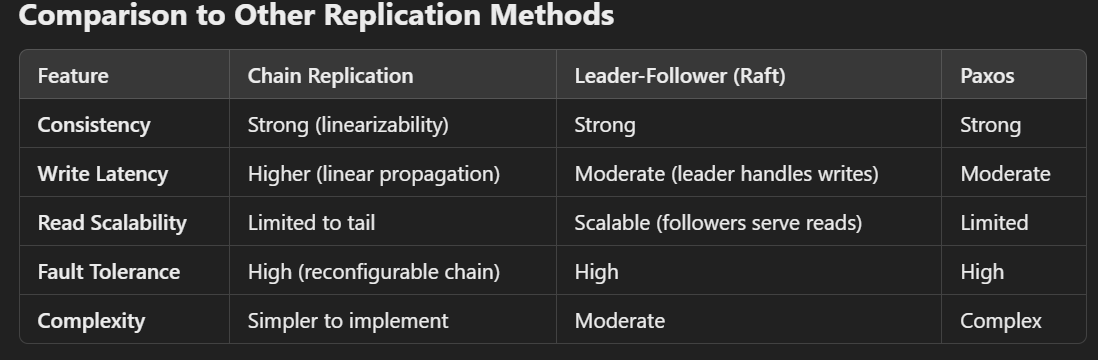
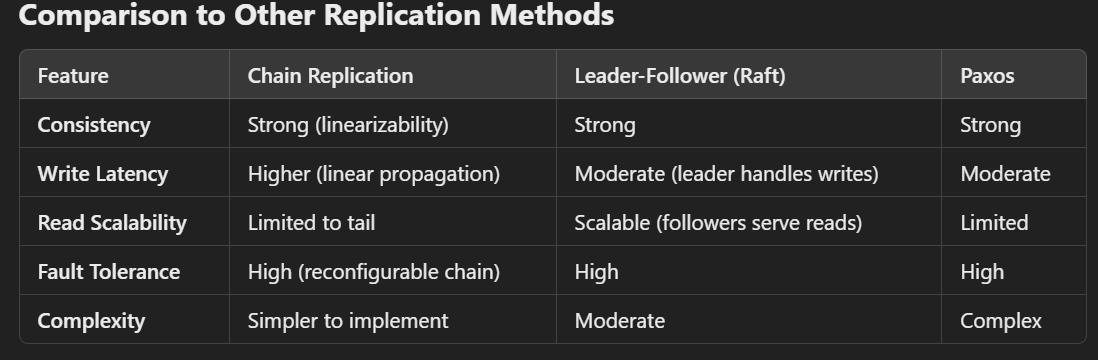
Advantages of Chain Replication
Strong Consistency:
Ensures linearizability (a guarantee that operations appear to be executed in a sequential order), as updates propagate sequentially through the chain.
Reads from the tail always return the most recent committed write.
Fault Tolerance:
The chain can handle node failures gracefully, ensuring high availability by reconfiguring the chain.
Deterministic Behavior:
Predictable read and write patterns simplify the design of consistency protocols.
Simplicity:
The sequential write-forwarding mechanism is simpler compared to more complex consensus protocols like Paxos or Raft.
Disadvantages of Chain Replication
Latency:
Writes take longer to complete because they must propagate through all nodes in the chain before being committed.
Single Point of Read:
All read requests go to the tail, which can become a bottleneck under high read loads.
Scalability:
The sequential nature of replication limits horizontal scalability compared to quorum-based approaches like Raft or Paxos.
Recovery Overhead:
When a node fails, reconfiguring the chain and restoring data to new nodes can introduce delays.
Load Imbalance:
The head and tail can become performance hotspots:
The head handles all writes.
The tail handles all reads.
When to Use Chain Replication
Chain replication is suitable for use cases where:
Strong Consistency is a top priority (e.g., financial applications, distributed logs, metadata services).
Write-heavy Workloads are more common than read-heavy workloads.
The system can tolerate higher write latencies for guaranteed consistency.
Fault-tolerance and deterministic failover are critical.
Examples of Chain Replication in Real Systems
Distributed Key-Value Stores:
Chain replication can be used in systems where key-value pairs need to be strongly consistent across nodes.
Storage Systems:
Systems like CRAQ (Chain Replication with Active Queries) extend chain replication to allow reads from intermediate nodes, improving read performance.
Database Metadata Services:
Chain replication is used in metadata stores, where ensuring the consistency of metadata is critical.
Causal Consistency Systems:
Systems that need ordered writes, such as distributed logging frameworks, may use chain replication for simplicity.