Why GFS is not designed to work in different data centers?
GFS (Google File System) was not designed to work across different data centers (i.e., geo-distributed environments) because of several core architectural assumptions .

🔧 1. Design Assumptions Optimized for a Single Data Center
Low latency, high bandwidth links were assumed between servers.
The system assumes reliable network partitions are rare — an assumption that breaks down over WANs (Wide Area Networks) due to higher latency, lower bandwidth, and frequent network partitions.
GFS assumes consistent time synchronization (e.g., for lease expiration), which is harder across geographically distributed sites.
📦 2. Master-Slave Architecture Not Suitable for Geo-Distribution
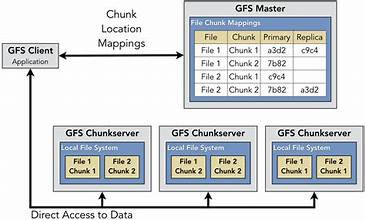
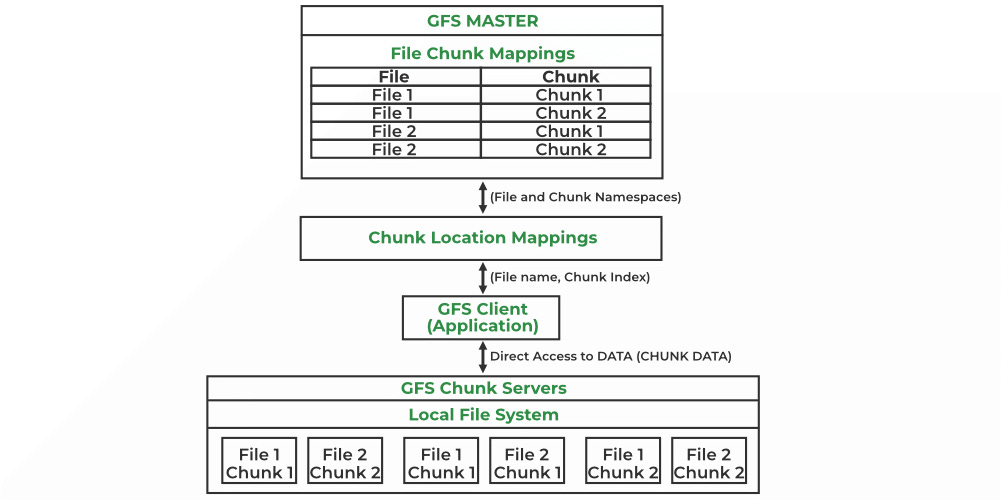
GFS uses a single master node that manages metadata for the entire file system.
A single master across multiple data centers would become a latency bottleneck and single point of failure over WANs.
Replicating the master across data centers adds consistency and coordination overhead, which GFS avoids by keeping the design simple and centralized.
⚖️ 3. Replication Strategy Assumes Fast Local Communication
GFS replicates each chunk (typically 64 MB) across 3 chunk servers within the same data center.
Cross-data-center replication would significantly increase replication latency and network costs.
🕒 4. Consistency Model Relies on Timely Heartbeats and Leases
Chunk lease mechanism depends on fast, predictable communication between the master and chunk servers.
Over WANs, delays or losses in lease renewal or heartbeats would lead to inconsistencies or performance degradation.
🏗️ 5. Failure Model Assumes Local Failures, Not Network Partitions
GFS is resilient to disk, node, and rack-level failures, not entire data center or WAN partition failures.
In multi-data center setups, network partitions are more common, making it harder to ensure availability and consistency.
| Limitation | Why it Matters |
| --------------------------------- | ------------------------------------------ |
| Assumes low-latency local network | WANs are slower and less reliable |
| Single master design | High latency + availability risks over WAN |
| Chunk replication within DC | Cross-DC replication = high cost and slow |
| Time-sensitive leases | Hard to maintain across DCs |
| Failure tolerance is local | Not resilient to data center partitioning |
🧠 Bonus: What Google Did Instead?
Google developed Colossus, the successor to GFS, which addressed several of these limitations with better metadata scalability, improved replication, and more modular architecture. For geo-distribution, systems like Spanner and F1 were designed from the ground up with global distribution and strong consistency guarantees.